Efektywne zarządzanie Protocoll Buffers z “Buf”. Wszystko, co powinieneś wiedzieć

Protocoll Buffers (protobuf) to język i niezależny format służący do serializacji danych. Jego główną zaletą jest to, że pozwala na szybkie i efektywne przesyłanie i przechowywanie danych, a także na ich łatwą integrację między różnymi językami i systemami.
Protobufy są oparte na prostych schematach, które opisują strukturę danych, takie jak pola i ich typy. Te schematy są następnie używane do generowania kodu w różnych językach programowania, takich jak C++, Java, Python, C#. Generalnie protobuff wspiera wiele języków, pełna lista jest dostępna pod tym linkiem.
Co ważne, protobufy są bardzo efektywne zarówno pod względem rozmiaru, jak i szybkości deserializacji oraz serializacji danych. Są też łatwe do rozszerzenia, co pozwala na dodawanie nowych pól bez konieczności zmiany istniejących kodów, co zwiększa elastyczność systemu.
Spis treści
Protocoll Buffers. Use cases
Protokół bufów może być używany w różnych sytuacjach, gdzie konieczne jest szybkie i efektywne przesyłanie oraz przechowywanie danych. Oto kilka przykładów:
- sieciowe komunikacje między systemami: Protokół bufów może być używany do przesyłania danych między różnymi systemami w sieci, np. między aplikacjami mobilnymi a serwerami,
- przechowywanie danych na przykład w bazach danych lub innych systemach przechowywania danych, takich jak pliki lub dane w chmurze,
- interfejsy API: Protokół bufów może być używany do definiowania formatu danych w interfejsach API,
- wymiana danych między mikroserwisami: Protokół bufów może być używany do wymiany danych między różnymi mikroserwisami w architekturze rozproszonej.
W niniejszym artykule skupię się na omówieniu tematyki komunikacji między mikroserwisami. Skupię się nie tylko na samej komunikacji, ale również na sposobach zachowania spójności protokołów między serwisami, wykorzystaniu definicji z różnych repozytoriów oraz uniknięciu niepożądanych błędów, na które możemy nie być świadomi podczas pracy nad swoim serwisem.
Jak zachować spójność Protocoll buffers
W architekturze mikroserwisów, gdzie różne serwisy mogą wymieniać się danymi za pomocą protokołu bufów, ważne jest, aby zachować spójność danych. Oto kilka sposobów, aby to osiągnąć:
- versioning schematów: Aby uniknąć problemów związanych z kompatybilnością między różnymi wersjami schematów, warto zaimplementować mechanizm wersjonowania schematów. W ten sposób, jeśli zmieni się struktura danych, serwis będzie mógł rozpoznać, która wersja schematu jest wymagana i dostosować się do niej,
- użycie kontraktów: Warto zdefiniować kontrakty dla interfejsów między serwisami, tak aby każdy serwis wiedział, jakie dane powinien otrzymać i jakie dane powinien wysłać,
- użycie narzędzi do testowania: Warto korzystać z narzędzi do testowania, takich jak WireMock, aby automatycznie testować, czy serwisy wymieniają się danymi zgodnie z oczekiwaniami,
- dokumentacja: Dokumentacja jest kluczowa dla utrzymania spójności protokółu bufów w architekturze mikroserwisów, zawierająca informacje na temat schematów, kontraktów i interfejsów między serwisami, co pozwala na łatwiejsze rozwiązywanie problemów,
- odpowiednio przygotowany CI/CD Pipeline,
- użycia odpowiedniego narzędzia na przykład Buf.
Szczególnie chciałbym skupić waszą uwagę na narzędziu, które się nazywa “Buf” i pokazać, jak dobrze skonfigurowane narzędzia mogą pomóc w zarządzaniu Protocoll Buffers.
Czym jest narzędzia Buf
Buf to narzędzie, które pomaga w zarządzaniu plikami protokołów w projektach opartych na protobuf. Narzędzie umożliwia automatyczne generowanie kodu dla różnych języków programowania oraz ułatwia proces aktualizacji i synchronizacji plików protokołów. Dzięki Buf, zespoły mogą łatwiej utrzymać porządek w swoich protokołach i zwiększyć efektywność pracy.
Na czym polega funkcjonalność tego narzędzia? Buf oferuje następujące możliwości:
- generowanie “stubs” dla różnych języków programowania,
- konsolidacja plików protokołów: Narzędzie pozwala na połączenie kilku plików protokołów w jeden, co ułatwia zarządzanie nimi,
- linter: Buf ma wbudowany linter, który sprawdza poprawność plików .proto, co pozwala na uniknięcie błędów i zwiększa czytelność kodu,
- aktualizacja plików protokołów: Narzędzie umożliwia łatwe aktualizowanie plików, co pozwala na szybkie reagowanie na zmiany,
- integracja z różnymi narzędziami: Buf może być łatwo zintegrowany z narzędziami takimi jak Git, Linter czy CI/CD Pipiline,
- wsparcie dla pluginów: Buf ma otwarty model pluginów, pozwala to na rozbudowanie funkcjonalności narzędzia oparte o własne rozwiązania.
No to teraz sprawdźmy, jak to rzeczywiście działa w praktyce.
Case study użycia
Załóżmy, że posiadamy aplikację e-commerce, która została zaimplementowana z wykorzystaniem architektury mikroserwisów. Aby lepiej zobrazować tę koncepcję, przyjrzyjmy się następującemu diagramowi:

Synchronizacja protokołów Protocoll Buffers jest ważnym tematem w kontekście komunikacji między mikroserwisami. Oto kilka sposobów, które pozwolą na zachowanie spójności protokołów:
- wykrywanie tak zwanych „breaking changes” na etapie pipeline CI/CD.
Oznacza to, że pipeline będzie blokować MR/PR, jeśli zostaną wprowadzone specyficzne zmiany w plikach .proto, które mogą popsuć działania innych serwisów.
- korzystanie z prywatnego menedżera pakietów, takiego jak Nexus, który będzie hostować wygenerowane pliki stubów. Dzięki temu, każdy mikroserwis będzie miał dostęp do tych samych plików,
- git repository jako jedyne źródło prawdy. Oznacza to, że definicje protokołów będą przechowywane w jednym repozytorium i każdy serwis będzie korzystał z nich.
Git repositorium może być dodane do `subtree` albo initializowane jako `submodule` dla tego microservisu.
W moim przypadku chciałbym umówić trzecią opcję – czyli jedno repozytorium na wszystkie definicje protobuff.

A jako effect końcowy to może przekonasz, albo i nie do czegoś takiego:
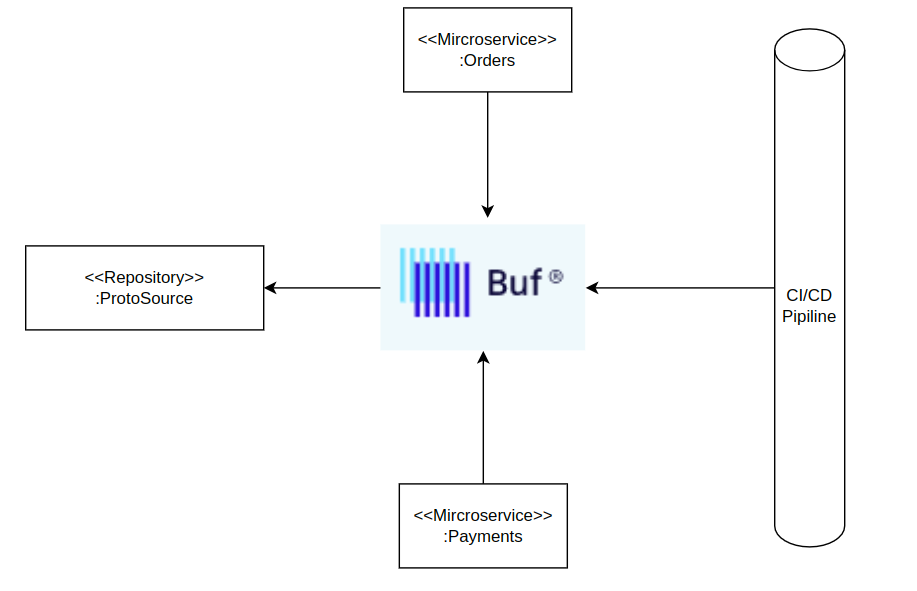
Załóżmy, że mamy następujące structure projektu i definicje .proto files dla ordersów oraz payments.
syntax = "proto3";
import "orders.proto";
service PaymentProcessor {
rpc CreatePayment(Order) returns (Payment);
}
enum PaymentMethods {
CASH = 0;
CREDIT_CARD = 1;
DEBIT_CARD = 2;
}
message Payment {
int64 payment_id = 1;
PaymentMethods method = 2;
Order order = 3;
}
syntax = "proto3";
service OrderProcessor {
rpc CreateOrder(Items) returns (Order);
}
message Order {
int32 order_id = 1;
string customer_name = 2;
float total_cost = 3;
string shipping_address = 4;
repeated Items items = 5;
}
message Item {
string name = 1;
int32 quantity = 2;
float cost = 3;
}
message Items {
repeated Item item = 1;
}
➜ proto git:(main) ✗ tree -r . └── payments.proto └── orders.proto 0 directories, 2 files
Chciałbym zacząć naszą przygodę z Buf z pierwszego narzędzia – Linter!
Linter
Tak mniej więcej wygląda workflow buf lintera:

Nie będziemy omawiać każdego problemu, który znajdzie linter, skupimy się raczej na tym, jak skonfigurować linter do swoich potrzeb. Standardowe konfiguracje narzędzia mogą nie pasować do każdego projektu. Możemy użyć konfiguracji dla różnych rzeczy, ale najpierw należy zainicjować środowisko dla naszego `buf` używając komendy
➜ proto git:(main) ✗ buf mod init
Która z kolei wygeneruje następujący plik
version: v1
breaking:
use:
- FILE
lint:
use:
- DEFAULT
W wygenerowanym pliku możemy określić dokładną konfigurację, w jaki sposób narzędzie Buf ma interpretować nasze pliki .proto. Używając poniższej komendy możemy sprawdzić, jaki błąd lintera odpowiada danej konfiguracji:
➜ proto git:(main) ✗ buf lint --error-format=config-ignore-yaml
version: v1
lint:
ignore_only:
ENUM_VALUE_PREFIX:
- proto_payments/payments.proto
ENUM_ZERO_VALUE_SUFFIX:
- proto_payments/payments.proto
PACKAGE_DEFINED:
- proto_orders/orders.proto
- proto_payments/payments.proto
PACKAGE_SAME_DIRECTORY:
- proto_orders/orders.proto
- proto_payments/payments.proto
RPC_REQUEST_RESPONSE_UNIQUE:
- proto_orders/orders.proto
- proto_payments/payments.proto
RPC_REQUEST_STANDARD_NAME:
- proto_orders/orders.proto
- proto_payments/payments.proto
RPC_RESPONSE_STANDARD_NAME:
- proto_orders/orders.proto
- proto_payments/payments.proto
SERVICE_SUFFIX:
- proto_orders/orders.proto
- proto_payments/payments.proto
Poprzez lekkie zmiany w konfiguracji, możemy ignorować niektóre polecenia lintera. Pełen zestaw konfiguracji znajdziecie pod tym linkiem.
Po wszystkich zmianach zaproponowanych przez linter Buf, nasza struktura repozytorium będzie wyglądać nie więcej tak:
➜ proto git:(main) tree -r . ├── protoc │ ├── payments │ │ └── v1 │ │ └── payments.proto │ ├── orders │ │ └── v1 │ │ └── orders.proto │ └── buf.yaml └── buf.work.yaml 5 directories, 4 files
Ponadto warto wspomnieć o pliku buf.work.yaml, który również jest plikiem konfiguracyjnym i wskazuje ścieżkę do plików .proto. W naszym przypadku wszystkie pliki znajdują się w folderze protoc, więc konfiguracja będzie wyglądać następująco:
version: v1 directories: - protoc
Polecam również rozszerzenie VS code IDE używające buf lintera (https://marketplace.visualstudio.com/items?itemName=bufbuild.vscode-buf).
Kolejnym ważnym feature narzędzia Buf jest BSR (Buf schema registry), o którym teraz pogadamy.
BSR (Buf schema registry)
Na tym etapie mogło powstać pytanie: „Jak możemy utrzymać synchronizację naszych plików protocoll buffers?”. Otóż, to jest właśnie funkcjonalność, która umożliwi nam to rozwiązanie.
Schema registry jest najważniejszą częścią tego postu, ponieważ pozwala nam na sprawne zarządzanie naszymi plikami .proto, a także generowanie stubów lokalnie bez konieczności instalowania pluginów i kompilatora w systemie. Czy naprawdę BSR jest takie potężne?
1. Centralized registry – BSR jest źródłem prawdy dla śledzenia i rozwijania swoich interfejsów API Protobuf. Rejestr centralny pozwala na utrzymanie kompatybilności i zarządzanie zależnościami, jednocześnie umożliwiając klientom pewne i efektywne konsumowanie interfejsów API.
2. UI and documentation – BSR oferuje kompletną dokumentację dla plików Protobuf przez przeglądarkowy interfejs z podświetlaniem składni, definicjami i odwołaniami.
3. Remote Plugins – Buf zarządza hostowanymi pluginami protobuf, które mogą być odwoływane w plikach buf.gen.yaml. Generowanie kodu odbywa się zdalnie na BSR i generowany kod źródłowy jest zapisywany na dysku.
4. Remote Packages – BSR udostępnia wygenerowane artefakty poprzez zarządzane repozytoria oprogramowania, które pobierasz jak każdą inną bibliotekę z narzędziami, których już używasz: go get lub npm install.
Na pierwszy rzut oka, taki registry może wydawać się bardzo podobny do znanego narzędzia „git”, ponieważ również tutaj mamy możliwość śledzenia historii zmian naszych plików proto, tworzenia draftów, tagów oraz przeglądania całej historii commitów.
Z czystym sumieniem polecam spróbowanie korzystania z jego UI, który jest jak najbardziej czytelny i przejrzysty, oraz pełnej i odpowiedniej dokumentacji do każdego pliku proto.
A teraz przejdźmy do kolejnej części – generowania kodu źródłowego – Stubs.
Generation
Aby lepiej przedstawić workflow, przyjrzyjmy się następującemu diagramowi:

Aby wygenerować stuby, potrzebny będzie plik `buf.gen.yaml`, który pozwala określić, co i w jakim języku możemy wygenerować. Jednak ważną różnicą między tymi podejściami jest to, że w przypadku remote feature, który został niedawno opublikowany, nie musimy mieć zainstalowanych żadnych kompilatorów w systemie, ponieważ generowanie odbywa się w BSR (Buf Schema Registry). To ma swoje wady i zalety, o których będziemy rozmawiać później.
Po wykonaniu tej komendy następujące stuby powinny pojawić się w naszym folderze:
➜ ~ buf generate
➜ proto git:(main) ✗ tree -r . ├── protoc │ ├── payments │ │ └── v1 │ │ └── payments.proto │ ├── orders │ │ └── v1 │ │ └── orders.proto │ └── buf.yaml ├── gen │ └── go │ ├── payments │ │ └── v1 │ │ └── payments.pb.go │ └── orders │ └── v1 │ └── orders.pb.go ├── buf.work.yaml └── buf.gen.yaml 11 directories, 7 files
Na koniec chciałbym przedstawić sprawdzanie plików .proto pod kątem tak zwanych „breaking” zmian.
Breaking changes
Jak w poprzednich przykładach zacznijmy może od workflow:

Polecenie `buf breaking –against` jest używane w narzędziu Buf do oznaczania zmian jako „breaking changes” (zmiany powodujące kompatybilność wsteczną) w porównaniu z określonym punktem w czasie.
Konkretniej, polecenie to porównuje bieżącą wersję pliku protokołu z wersją podaną jako argument –against i oznacza jakiekolwiek różnice jako „breaking changes”. To pozwala na łatwe zidentyfikowanie zmian, które mogą mieć wpływ na istniejące implementacje protokołu i pozwala na wcześniejsze zidentyfikowanie oraz rozwiązanie ewentualnych problemów związanych z kompatybilnością wsteczną.
Są różne sposoby użycia tej komendy, natomiast najważniejsze jest to, że pomoże nam wykryć jakiś breaking zmiany w naszych plikach w porównaniu do tego samego w git/archiwu/tagu I id.
Używając następującej komendy – `buf breaking –against „.git#branch=main”` możemy sprawdzić, czy nasze zmiany nie zepsuły czegoś w porównaniu do wersji, którą mamy w git reposytorium `main` branch, lub używając komendy – `buf breaking –against „v1.0.0″` spowoduje porównanie bieżącej wersji .proto plików z wersją „v1.0.0” i oznaczenie wszelkich różnic jako „breaking changes”.
Protocoll Buffers. Podsumowanie
Buf to narzędzie, które ma na celu usprawnienie procesu tworzenia, testowania i publikowania protokołów oraz formatów plików. Warto ponownie podkreślić jego główne wady i zalety.
Do zalet zaliczamy:
- automatyzacja procesów: Buf pozwala na automatyzację procesów związanych z tworzeniem, testowaniem i publikowaniem protokołów i formatów plików, co pozwala na zwiększenie efektywności i zmniejszenie ryzyka błędów,
- jednolity format plików: Buf umożliwia tworzenie, testowanie protokołów i formatów plików w jednolitym formacie, co pozwala na łatwiejszą współpracę między różnymi narzędziami i systemami,
- integracja z narzędziami do kontroli wersji: Buf integruje się z narzędziami do kontroli wersji, takimi jak Git, co pozwala na łatwiejszą zarządzanie historią zmian i udostępnianie protokołów i formatów plików innym osobom,
- generacja stubs bez konieczności instalowania complailers lokalnie,
- BSR posiada jasny i przejrzysty UI. Dokumentacja out of the box,
- zestaw korzystnych CLI comend, taki jak `lint`, `build`, …
- croffplatformowe narzędzie.
Natomiast są też wady korzystania z tego narzędzia:
- ograniczona liczba obsługiwanych języków: Obecnie Buf obsługuje tylko kilka języków, takich jak Go, Java i Python, co ogranicza jego zastosowanie do projektów napisanych w tych językach,
- możliwe problemy z kompatybilnością: Buf jest narzędziem, które może generować pliki w różnych formatach, co może powodować problemy z kompatybilnością z innymi narzędziami lub systemami,
- kompleksowość: Narzędzie składającym się z wielu różnych składników i konfiguracji, co może być trudne do opanowania dla początkujących użytkowników,
- ryzyko dostępności: To jest dość ryzykowna decyzja budować na przykład CI/CD Pipeline polegając na zewnętrznym narzędziu, bo w momencie jego niedostępności cały development będzie zablokowany.
Zdjęcie główne artykułu pochodzi z unsplash.com.
Podobne artykuły

Pythonic way. Jak pisać czysty kod w Pythonie?

GraphQL to ciekawostka w cv czy must have?

REST API w Pythonie: Flask czy FastAPI?
