Wzorce odporności na awarie w systemach rozproszonych

Tworzenie systemów rozproszonych wiąże się z koniecznością radzenia sobie z wieloma nowymi problemami, niespotykanymi zwykle w aplikacjach działających jako jeden proces.
Spis treści
Wstęp
Wewnątrz pojedynczego procesu możemy być pewni, że wywołana funkcja zostanie wykonana, a zaraz po jej zakończeniu otrzymamy rezultat lub informację o błędzie (w postaci zwróconej wartości lub wyjątku). W systemach rozproszonych nie mamy takich gwarancji. Wiadomości między serwisami mogą się gubić lub docierać w niewłaściwej kolejności, serwery mogą ulegać awarii, połączenia sieciowe mogą zostać zerwane lub, w przypływie nagłej popularności usługi, serwery mogą zostać zasypane nadmierną liczbą zapytań, których nie będą w stanie obsłużyć.
Często od nowoczesnych systemów wymaga się wysokiej dostępności. Z drugiej strony, wszystkie ich składowe (oprogramowanie, sieć, dyski, komputery itd.) są do pewnego stopnia zawodne. Problemy z jednym komponentem mogą powodować kaskadowe wystąpienie problemów w innych częściach systemu, prowadząc w ten sposób nawet do jego całkowitej niedostępności.
W dalszej części artykułu poznamy niektóre z powszechnie stosowanych wzorców pozwalających na projektowanie systemów, które będą do pewnego stopnia odporne na częściowe awarie. Tę cechę określa się mianem fault tolerance.
Redundancja
Części systemu, których awaria może spowodować jego całkowitą niedostępność, określane są jako pojedyncze punkty awarii (ang. single point of failure). Wyeliminowanie ich pozwoli nam poprawić dostępność systemu i jego odporność na błędy.
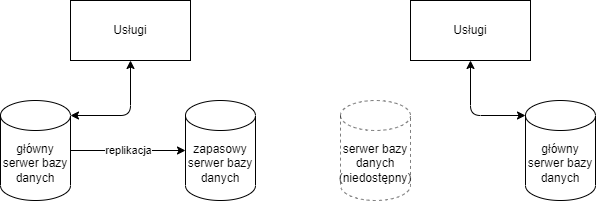
Często serwery baz danych stanowią pojedynczy punkt awarii w aplikacjach. Większość powszechnie stosowanych RDBMS (Relational Database Management System) może zostać skonfigurowana, aby działać w trybie wysokiej dostępności (high availability). Wtedy, oprócz głównego serwera (primary), działa także co najmniej jedna jego replika – serwer zapasowy (secondary), gotowy w trakcie awarii przejąć jego rolę.
Pomiędzy serwerami danych może zachodzić replikacja synchroniczna. To znaczy, że każda operacja wykonana na głównym serwerze musi być natychmiast wykonana na serwerze zapasowym. Replikacja synchroniczna spowalnia wykonanie wszystkich operacji, ponieważ wymaga potwierdzenia każdej z nich przez serwer zapasowy, ale w przypadku awaryjnego przepięcia (ang. failover) gwarantuje brak utraty danych. Drugą opcją jest replikacja asynchroniczna, gdzie serwer zapasowy może wykonywać operacje z opóźnieniem. Przy użyciu replikacji asynchronicznej i konieczności awaryjnego przepięcia, serwer zapasowy, przejmujący teraz rolę serwera głównego, może nie posiadać najnowszych zmian, które zostały niedawno wykonane.
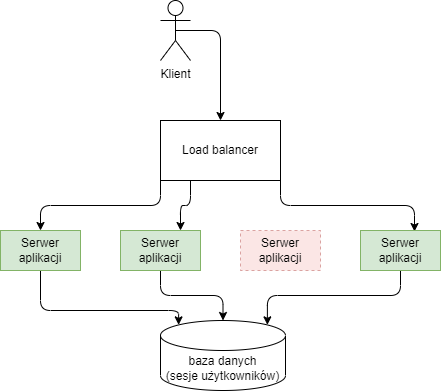
Aby usługa nie stała się pojedynczym punktem awarii, musi być uruchomiona co najmniej na dwóch serwerach, z którymi użytkownik komunikuje się za pośrednictwem mechanizmu równoważenia obciążenia (ang. load balancer). W przypadku wystąpienia awarii jednego z serwerów, może on wykryć ten błąd za pomocą mechanizmu health check i przestać przekierowywać ruch do tego serwera, dopóki usterka nie ustanie. Takie rozwiązanie pozwala również na skalowanie liczby serwerów w odpowiedzi na zwiększone obciążenie.
Wykorzystanie mechanizmu równoważenia obciążenia powoduje, że kolejne zapytania od jednego użytkownika mogą trafiać do różnych maszyn. Jeżeli przechowują one dane powiązane z sesją użytkownika w pamięci, może to skutkować tym, że dane pozornie “znikają”. Na przykład, sklep internetowy przechowujący zawartość koszyka w pamięci serwera może “zgubić” poprzednio dodane towary.
Można skonfigurować load balancer, tak żeby wszystkie zapytania w ramach jednej sesji użytkownika powiązane były zawsze z jednym serwerem (tzw. session affinity). Pozornie rozwiązuje to problem, ponieważ przy normalnym działaniu użytkownik będzie widział spójny widok koszyka w ramach jednej sesji. Co jednak w przypadku awarii tego jednego serwera? Polecanym rozwiązaniem tego problemu jest uczynienie serwerów bezstanowymi i przechowywanie sesji użytkownika w osobnej bazie danych.
Timeout
Kiedy procesy komunikują się po asynchronicznej sieci (takiej jak Internet), maksymalny czas dostarczenia wiadomości jest nieograniczony. Może ona także zostać porzucona, nie docierając do odbiorcy.
Jeżeli wyślemy wiadomość, na którą nie otrzymaliśmy odpowiedzi, nie ma sposobu stwierdzenia, czy:
- wiadomość zaginęła po drodze (nie dotarła do odbiorcy),
- lub wiadomość dotarła do odbiorcy, ale w trakcie jej przetwarzania nastąpił błąd,
- lub wiadomość dotarła do odbiorcy i jest w trakcie przetwarzania,
- lub wiadomość dotarła do odbiorcy i została przetworzona, ale odpowiedź nie dotarła do nas.
Oczekiwanie w nieskończoność na odpowiedź, która może nigdy nie dotrzeć, prowadzi do blokowania wątków i połączeń a także może być przyczyną dalszych błędów. Rozwiązaniem tego problemu jest stosowanie timeoutu, czyli ograniczonego czasu oczekiwania na odpowiedź i traktowanie każdej sytuacji, gdzie ten czas został przekroczony, jako błąd.
Kiedy sami tworzymy logikę komunikacji z innymi serwerami, sami też jesteśmy odpowiedzialni za właściwe zaimplementowanie mechanizmu timeoutu. Używając gotowych bibliotek warto sprawdzić, czy posiadają konfigurację timeoutu i dostosować ją do naszych potrzeb. Często domyślne wartości mogą nie odpowiadać naszemu użyciu.
Zbyt krótki timeout może skutkować częstym porzucaniem zapytań, które niedługo później zakończyłyby się sukcesem. Zbyt długi natomiast spowolni działanie systemu i zablokuje zasoby w sytuacji, kiedy otrzymanie odpowiedzi jest już mało prawdopodobne.
Jak więc dobrać długość timeoutu? Nie ma jednej, uniwersalnej wartości, która zadziała wszędzie. Warto jednak wziąć pod uwagę z jednej strony wymagania biznesowe (jak długo użytkownik będzie miał cierpliwość czekać na odpowiedź), a z drugiej realny, zmierzony przez nas czas odpowiedzi od serwera w różnych sytuacjach.
Retry
Co możemy zrobić, kiedy zapytanie do serwera zakończyło się niepowodzeniem? Jednym z rozwiązań jest ponowienie zapytania po krótkim czasie. Nie mamy jednak pewności, czy oryginalne zapytanie zostało poprawnie obsłużone, czy nie. Bezpiecznie powtarzać możemy tylko te zapytania, które są idempotentne, to znaczy, że jeżeli wykonamy je kilka razy, to stan systemu będzie taki sam, jakby zostały wykonane tylko raz.
Zasadność ponawiania zapytania zależy od tego, czy konkretny błąd, który wystąpił uważamy za przemijający (ang. transient) czy też wskazuje on na to, że zapytanie jest niepoprawne i za każdym razem zakończy się błędem. Określenie, które błędy są przemijające może wymagać wiedzy o protokole, za pomocą którego komunikujemy się z serwerem lub przeanalizowania możliwych wyjątków lub kodów błędów. Przykładowo w protokole HTTP, kody odpowiedzi z zakresu 500-599 wskazują na błąd serwera i mogą być potencjalnie rozwiązane po ponowieniu zapytania.
Często stosowanym schematem jest exponential backoff, czyli kilkukrotne ponawianie prób wykonania zapytania w wykładniczo rosnących odstępach czasowych (na przykład najpierw po 1 sekundzie, potem po 2, po 4, po 8 i po 16). Jest on korzystny, ponieważ unika zasypywania serwera dużą ilością zapytań, jeżeli błędy wynikają z nadmiernego jego obciążenia.
Fallback
Innym sposobem radzenia sobie z awariami zewnętrznych systemów jest posiadanie planu awaryjnego (ang. fallback). Na przykład załóżmy, że tworzymy serwis streamujący filmy i chcemy wyświetlić użytkownikowi listę sugerowanych pozycji do obejrzenia. Podstawowym sposobem zrealizowania tej funkcjonalności może być wykonanie zapytania do osobnego serwisu odpowiedzialnego za stworzenie spersonalizowanej listy propozycji, na podstawie indywidualnej historii przeglądania każdego użytkownika. Jeżeli takie zapytanie zawiedzie, bo np. serwis za nie odpowiedzialny jest niedostępny, możemy mieć plan awaryjny i, zgodnie z zasadami graceful degradation, wyświetlić użytkownikowi wcześniej przygotowaną statyczną listę najpopularniejszych pozycji – taką samą dla wszystkich.
Circuit Breaker
Wzorzec Retry opiera się na optymistycznym założeniu, że krótko trwający błąd, który wystąpił przy ostatnim wykonaniu operacji, przeminie i następnym razem zakończy się ona sukcesem. Co jednak w sytuacji dłużej trwającej awarii? Może zostało zerwane połączenie sieciowe do serwera lub jest on pod nadmiernym obciążeniem i nie może obsłużyć więcej ruchu? W takich sytuacjach pomocny dla nas będzie wzorzec Circuit breaker – nazwany tak przez analogię do bezpiecznika w systemach elektrycznych. Może znajdować się on w jednym z trzech stanów: zamkniętym, otwartym albo półotwartym:
- W stanie zamkniętym zapytania wykonywane są normalnie.
- W stanie otwartym zapytania nie są wykonywane, a skutkują natychmiastowym błędem.
- Stan półotwarty “przepuszcza” kilka zapytań w celu sprawdzenia, czy serwer wrócił do poprawnego działania. Jeżeli którekolwiek z nich zakończy się niepowodzeniem, circuit breaker wraca do stanu otwartego. Jeżeli wszystkie się powiodły, zakładamy, że awaria się zakończyła i circuit breaker przechodzi do stanu zamkniętego.
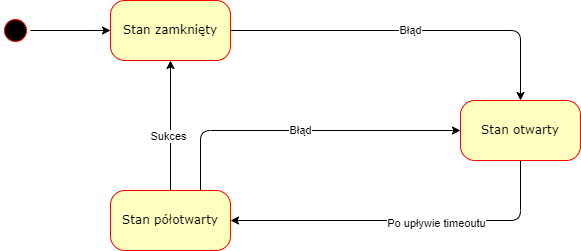
Circuit breaker nie jest przeciwieństwem wzorca Retry. Mogą być one skutecznie stosowane w połączeniu ze sobą. Wtedy pojedyncze, przemijające błędy będą skutkowały ponowieniem operacji. Z kolei seria zapytań zakończona niepowodzeniem spowoduje otwarcie circuit breakera i powstrzymanie wykonywania zapytań, aż serwer znów nie zacznie odpowiadać poprawnie.
Cache
Zastosowanie cache przy wykonywaniu zapytań pozwala znacznie zmniejszyć obciążenie serwera poprzez pamiętanie wyników poprzednich zapytań z tymi samymi parametrami i zwrócenie ich. Należy jednak pamiętać, że przypadku wykorzystania cache, otrzymane dane nie muszą być aktualne, a mogły zostać pozyskane wcześniej i zapamiętane. To, czy taka sytuacja jest dopuszczalna, zależy od wymagań biznesowych (np. czy jest to akceptowalne z punktu widzenia klienta) oraz modelu spójności danych w systemie.
Cache’owane dane mogą być przechowywane osobno w pamięci każdej maszyny lub współdzielone poprzez wykorzystanie serwera cache (popularnymi rozwiązaniami są na przykład Memcached lub Redis). Niezależnie od przyjętego rozwiązania, pamięć dostępna do przechowywania wartości w cache jest ograniczona. Może nastąpić potrzeba zwolnienia jej poprzez usunięcie części poprzednio zapamiętanych wartości. Niektóre mechanizmy cache pozwalają na wybór strategii wyboru wartości do usunięcia. Do najpopularniejszych należą:
- najdawniej używana (ang. Least Recently Used – LRU),
- najrzadziej używana (ang. Least Frequently Used – LFU),
- losowa.
Dane, które przechowujemy w cache mogą zmieniać się w czasie. Aby zapewnić, że nie udostępniamy zbyt starych wartości, możemy skonfigurować tzw. TTL (Time To Live) – czyli maksymalny czas przechowywania danych w cache, po którym są one automatycznie usuwane.
Podobne artykuły

Języki programowania, które trzeba znać w 2025 roku

Rozwój bez granic: jak Spyrosoft łączy lokalne doświadczenie z globalną skalą projektów

25 lat zmian w IT. A my nadal tu jesteśmy – bo potrafimy się uczyć

Jak rozwijać kompetencje społeczne w świecie IT?

Czym jest i jak powstaje eazle – The Engine of HEINEKEN's eCommerce?

Appunite vs zwykła agencja – co można tu, czego nie można tam?

IT czeka na kobiety – rozmowa z Zuzanną Dylęgowską
