Ruby a metody uczenia maszynowego
Nie jest tajemnicą, że najczęściej wykorzystywanymi językami w przypadku metod sztucznej inteligencji są Python, Java, Scala oraz R. Istnieje również kilka niszowych języków, które są dedykowane do tego typu rozwiązań jak np. Julia. W przypadku Pythona jego popularność przy wykorzystaniu sztucznej inteligencji wynika z tego, że poza szybkością (dzięki bibliotekom) oraz prostotą, ma prawdopodobnie największą liczbę bibliotek metod uczenia maszynowego.

Karol Przystalski. Założyciel Codete. Jego rola polega na wsparciu zespołu i mentoringu. Otrzymał tytuł Doktora Nauk Technicznych w Instytucie Podstawowych Problemów Techniki Polskiej Akademii Nauk, jest adiunktem na Uniwersytecie Jagiellońskim w Krakowie. W Codete stworzył dział badawczy pracujący nad zastosowaniem metod uczenia maszynowego oraz rozwiązań big data, w szczególności w obszarze rozpoznawania obrazów oraz HDP.
Java i jej powiązanie ze sztuczną inteligencją wynika z faktu, że jest to jeden z najczęściej używanych języków i siłą rzeczy powstało wiele przydatnych bibliotek. Dzieje się tak m.in. dlatego, że Java ma silną pozycję w tworzeniu oprogramowania dla sektora Enterprise, które jest szczególnie zainteresowane omawianym tutaj obszarem, dodatkowo, ogromna społeczność tego wokół języka zrobiła swoje.
W przypadku Scali na jej korzyść przemawia Spark i jego część dedykowana uczeniu maszynowemu. R natomiast od samego początku został stworzony jako język pod statystykę, a jak wiadomo od statystyki do metod sztucznej inteligencji nie jest zbyt daleko. Dzięki temu R dał się poznać jako dobry język pod kątem właśnie metod sztucznej inteligencji. Czy w najbliższej przyszłości istnieje szansa, aby jeszcze któryś język wybił się i zdobył popularność ze względu na jego wykorzystanie do metod uczenia maszynowego?
W tym artykule przedstawiliśmy kilka podstawowych narzędzi wykorzystywanych przy projektach typu machine learning w języku Ruby, który od wielu lat znany jest ze swoich zastosowań do budowania aplikacji internetowych.

Spis treści
Przygotowanie oraz obróbka danych
Analizę rozpoczniemy od zastosowania bibliotek napisanych w języku Ruby do przygotowania, oraz walidacji danych. Proces przygotowania danych jest często jednym z najważniejszych, gdy chcemy wyciągnąć dodatkowe informacje z posiadanych danych. Dane często bywają nieustrukturyzowane, lub zaszumione i muszą zostać odpowiednio przygotowane przed dalszą analizą. Do tego celu najlepiej nadają się tzw. DataFrames, których implementację w Pythonie można znaleźć np. w pakiecie Pandas. W Ruby od pewnego czasu dość prężnie działa społeczność skupiona wokół analizy danych.
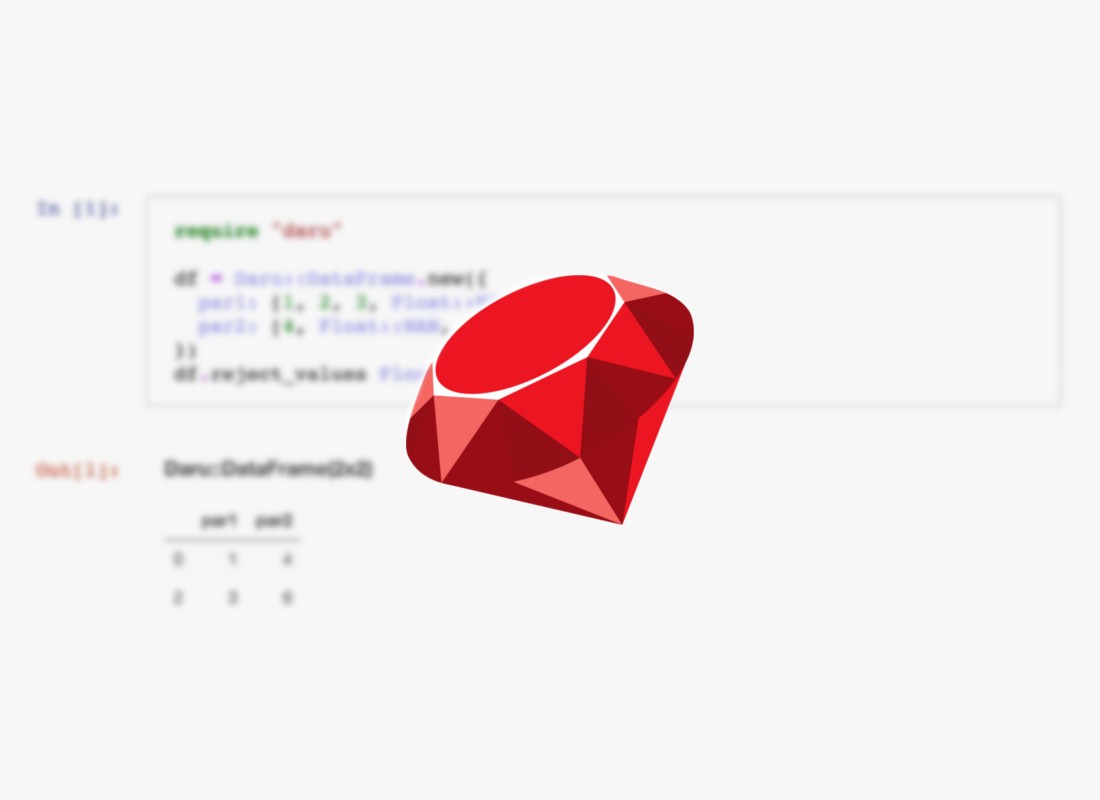
Jedną z bibliotek, która jest rozwijana w ramach grupy SciRuby jest Daru będący odpowiednikiem Pandas w Ruby. Daru nie posiada tak wielu funkcjonalności jak Pandas, niemniej te najczęściej używane funkcjonalności zostały zaimplementowane. Implementacja rozwiązania opartego na Daru tylko nieznacznie różni się od tego w Pandas. Przykład odfiltrowania brakujących danych za pomocą Daru przedstawiony został na rysunku 1. Istnieje wiele innych metod na uzupełnienie lub usunięcie danych, które są szumem, lub odrzucenie tych przypadków, które są niepełne.

Rys. 1. Przykład filtrowania wadliwych danych za pomocą Daru
Istnieje również kilka klasycznych zestawów danych jak np. Iris, które możemy zaimportować do Daru. Można wykorzystać same zestawy za pomocą pakietu datasets lub datasets-daru, który pozwala na eksport danych bezpośrednio do Daru. Przykład taki został przedstawiony na rysunku 2. Jest jeszcze kilka bibliotek, które realizują ideę DataFrame’ów, ale tylko Daru jest warte uwagi.

Rys. 2. Przykład wyświetlenia pierwszych trzech rekordów bazy Iris za pomocą Daru
W analizie nie braliśmy pod uwagę narzędzi do obsługi czy manipulacji danymi, które znajdują się w bazach danych, np. do obsługi MongoDB. Narzędzia te również mogą zostać wykorzystane do przetwarzania danych.
Klasyfikacja
Ruby nie jest jedynym językiem ubogim w biblioteki uczenia maszynowego. Społeczność skupiona wokół projektu SciRuby rozwija wiele bibliotek dla języka Ruby w tym obszarze. Wiele z tych bibliotek jest jednak już dość stara. Zwłaszcza dotyczy to bibliotek, gdzie występują metody płytkie. Jednocześnie starość nie jest dużą wadą tych bibliotek, ponieważ wiele problemów klasyfikacji można rozwiązać za pomocą klasycznych metod płytkich. Jednym z takich przykładów są paczki rb-libsvm, liblinear-ruby czy decisiontree wykorzystujące natywne biblioteki. Odbywa się to podobnie jak w przypadku rb-libsvm, która to korzysta z dobrze znanej biblioteki libsvm oraz klasyfikatora SVM.
Istotną biblioteką, która jest rozwijana w ramach SciRuby jest iRuby, która pozwala na obsługę języka Ruby na platformie Jupyter. Instalacja tego rozszerzenia nie jest jednak tak prosta jak w przypadku języków JavaScript czy Python. Przy tym, nie jest również w pełni funkcjonalna, ponieważ brakuje jej m.in. tzw. magics. Pomimo tych niedogodności, jest to bardzo ważny krok naprzód w kontekście budowania rozwiązań opartych na uczeniu maszynowym.

Rys. 3. Wykorzystanie PyCall do wywołania bibliotek w Pythonie na przykładzie scikit-learn
Niestety brakuje wsparcia dla wielu popularnych rozwiązań znanych z Pythona, a te które istnieją oparte są o PyCall, czyli wywołują metody z bibliotek napisanych w Pythonie. Przykład takiego wywołania przedstawiony został na rysunku 3. Nie jest to najlepsze rozwiązanie, ale z pewnością jest ono jednym z szybszych jeżeli chodzi o stworzenie wrappera danego rozwiązania dla języka Ruby. W ten sposób zbudowany został wrapper dla Tensorflow, który jest obecnie najpopularniejszą biblioteką do tworzenia modeli głębokiego uczenia (deep learning). Istnieje jeszcze natywne rozszerzenie Tensorflow za pomocą tensorflow.rb, ale ta biblioteka wydaje się nie być rozwijana.
Porównanie
Na poziomie języków programowania możemy porównać wsparcie w języku Ruby do najbardziej rozchwytywanych np. Python, oraz do tych, które nie są pierwszym wyborem przy tworzeniu rozwiązań opartych o uczenie maszynowe. Ograniczymy się jedynie do tej drugiej grupy, ponieważ nie chodzi o kolejny roast języka Ruby. Do tej drugiej grupy możemy z pewnością zaliczyć JavaScript. W przypadku tego języka, istnieje znacznie więcej bibliotek w porównaniu do Ruby, jednocześnie wiele z tych bibliotek jest napisana słabo pod kątem jakości kodu lub ich biblioteki nie są kompletne. Niemniej, JavaScript może się pochwalić większą liczbą dostępnych rozwiązań. Łatwiej jest też z wykorzystaniem procesorów graficznych do obliczeń. To wcale nie oznacza, że w Ruby się nie da.
Porównując Ruby do innych języków, wsparcie tego języka dla uczenia maszynowego jest średnie. Jedną z niewielu przewag języka Ruby, nawet w stosunku do Pythona, jest dostępność wielu bibliotek do wizualizacji, np. rubyvis czy gruff. Przykład zastosowania tej drugiej widoczny jest na rysunku 4.

Rys. 4. Wykorzystanie gruff do stworzenia wykresu danych z bazy Iris
Kolejne kroki
Istnieje wiele opinii, że jest kilka odpowiednich języków, od których należy zacząć pracę nad projektami z uczeniem maszynowym. Z pewnością łatwiej jest zacząć w języku Python, niż w języku Ruby. Obecnie programiści Ruby wykorzystują do tego inne języki np. Java czy Python, które używane są są jako osobny serwis, do którego odwołują się aplikacje napisane np. w języku Ruby. Dotyczy to wielu języków, nie tylko Ruby. Jest to wygodne i pozwala w łatwy sposób na oddzielenie pracy analityków od programistów. Z drugiej strony w wielu przypadkach lepszym rozwiązaniem będzie zastosowanie modeli bezpośrednio w projekcie. Wtedy należy szukać wrapperów czy poszukać rozwiązań typu protobuf.

Obecnie większość obliczeń, w szczególności do trenowania, wykonywanych jest na procesorach graficznych (GPU/TPU), które są niezależne od języka programowania. Nie warto więc zawsze przykładać zbytniej wagi do samego języka, ponieważ największa praca poza samymi obliczeniami na procesorach to obróbka, oraz przygotowanie danych, które można wykonać wykorzystując większość języków. Jednym z takich języków jest Ruby. Należy jednak pamiętać o tym, że pomimo tego, że większość obliczeń jest wykonywana na procesorach graficznych, wiele języków, w tym Ruby, pomimo wsparcia dla procesorów graficznych, wymaga dużego nakładu pracy w napisanie odpowiednich metod uczenia maszynowgo zdolnych do wykorzystania wsparcia GPU.
Wynika to z niewielkiej liczby niskopoziomowych bibliotek, np. do obliczeń numerycznych, które takie obliczenia mogłyby optymalnie przerzucić na procesory graficzne. Jest jednak nadzieja, ponieważ społeczność SciRuby pracuje nad takimi bibliotekami. Podobnie było z Pythonem, z tą różnicą, że w Pythonie zostało to już zrobione wiele lat temu.
Podobne artykuły

Bukmacher kontra gracz - czyli o tym, jak zbudowaliśmy generator kuponów oparty na statystykach sportowych

O krok przed innymi. Ericsson współpracuje z Instytutem Telekomunikacji AGH

Rola cyfryzacji we wdrażaniu gospodarki o obiegu zamkniętym. Wywiad z Dariuszem Doberem

Optymalizacja pamięci. Jak zredukować rozmiar wektorów

Samodiagnozowanie stanu zdrowia przy użyciu AI będzie możliwe już niedługo? Wywiad z Przemkiem Jaworskim z MX Labs

W poszukiwaniu podobnych. Od wyzwania do produktu – machine learning w praktyce

Data Analytics, Data Science, Machine Learning – co wybrać?
