Jak za pomocą sztucznej inteligencji walczy się z internetowymi złodziejami

Wszyscy mówią i piszą dziś o sztucznej inteligencji. A.I. to jeden z najmodniejszych akronimów świata technologii i biznesu, często stosowany bezrefleksyjnie lub w sposób niejasny. Poniżej podejmuję próbę prostego wytłumaczenia, czym jest sztuczna inteligencja i w jaki sposób wykorzystuje się ją w biznesie. O zjawisku opowiadam na przykładzie detekcji wyłudzeń w handlu internetowym, gdzie uczenie maszynowe pozwala już dziś osiągać rezultaty jeszcze kilka lat temu niewyobrażalne dla specjalistów w dziedzinie zarządzania ryzykiem.
Pisarze i dziennikarze często opowiadają o sztucznej inteligencji, animizując czy wręcz personifikując maszyny. Nic w tym dziwnego – zjawisko jest głęboko zakorzenione w kulturze masowej, w szczególności w literaturze i kinie z gatunku science fiction. Wszyscy mamy zwyczaj myśleć przez analogie, dlatego też łatwo wpaść w pułapkę wyobrażania sobie sztucznej inteligencji jako osadzonego w maszynie superumysłu w stylu komputera HAL 9000 z filmu „2001: Odyseja kosmiczna” lub – idąc dalej – jako humanoidalnego, myślącego robota, jak T-1000 z serii “Terminator”.
Spis treści
Czym jest właściwie sztuczna inteligencja?
Choć korzystając z wirtualnego asystenta, jak Siri czy Alexa, można czasem odnieść wrażenie, że wizja rodem z filmów już się urzeczywistniła lub czeka nas lada dzień, w istocie jesteśmy od niej wciąż stosunkowo daleko. Owszem, idea tzw. „silnej sztucznej inteligencji” (ang. Artificial General Intelligence), czyli maszyny zdolnej wykonać dowolne zadanie intelektualne, jakie wykonać może człowiek, często pobudza fantazję i emocje, jednak dyskusje na ten temat pozostają na razie raczej domeną futurologów.
Użyłem terminu „idea” celowo. Sztuczna inteligencja jest ideą – w dodatku o bogatej historii. Niektórzy doszukują się jej korzeni już w starożytności, jednak jej współczesne wydanie narodziło się dopiero w latach 50 XX wieku. W myśl tej idei, maszyna jest w stanie samodzielnie wykonywać różne zadania w sposób inteligentny, to znaczy nie według określonego programu, lecz na podstawie własnych wniosków z analizy dostarczonych jej danych.
Jedynym znanym dziś ludzkości urzeczywistnieniem tej idei jest uczenie maszynowe (ang. Machine Learning). Polega ono na samodzielnym realizowaniu przez komputer działań prowadzących do wykonania określonego zadania, z wykluczeniem bezpośredniego programowania przez człowieka. Jest to możliwe m.in. dzięki zastosowaniu algorytmów, które dokonują analizy informacji w sposób wzorowany na funkcjonowaniu ludzkiego mózgu.
Kluczowe znaczenie dla powodzenia procesu uczenia mają typy i jakość danych, na podstawie których komputer, a właściwie wykonywany przez niego algorytm, jest trenowany (uczony). Istnieje wiele różnych metod i technik uczenia maszynowego, jak choćby uczenie pod nadzorem (ang. supervised machine learning), uczenie bez nadzoru (ang. unsupervised machine learning), uczenie pod częściowym nadzorem (ang. semi-supervised machine learning) czy uczenie przez wzmocnienia (ang. reinforcement machine learning). Każda z metod ma inne zastosowanie.
Uczenie pod nadzorem wymaga dostarczenia do modelu zbioru obserwacji i odpowiadających im odpowiedzi (wartości numerycznych, które model ma przewidywać). Jest to tzw. zbiór treningowy. Zadaniem modelu jest nauczenie się związku między obserwacją a odpowiedzią. Kluczowe znaczenie ma to, aby model przewidywał odpowiedź możliwie trafnie dla obserwacji spoza zbioru treningowego.
Uczenie bez nadzoru, z kolei, nie wymaga dostarczenia odpowiedzi (stąd określenie „bez nadzoru”), a polega bardziej na znalezieniu ukrytych zależności upraszczających opis obserwacji. Jednym z zastosowań uczenia bez nadzoru jest tzw. redukcja wymiarowości, w której wielowymiarowe obserwacje przedstawiane są w bardziej zwięzłej postaci, jednakże bez nadmiernej utraty informacji.
Uczenie pod częściowym nadzorem czerpie z obydwu powyższych podejść, gdzie dla części obserwacji znamy właściwe odpowiedzi, a dla części nie.
Uczenie przez wzmacnianie zaś jest metodą wyznaczania optymalnej polityki sterowania przez model w nieznanym mu środowisku, na podstawie interakcji z tym środowiskiem. Jedyną informacją, na której model się w tym przypadku opiera jest sygnał wzmocnienia, który osiąga wysoką wartość (nagrodę), gdy model podejmuje poprawne decyzje lub niską (karę), gdy podejmuje decyzje błędnie. Mechanizm ten jest wzorowany na podejściu behawioralnym w psychologii.
Powyższe przykłady mają na celu podkreślenie, że sztuczna inteligencja nie jest żadną czarodziejską szkatułą, do której można „włożyć” dowolne informacje i zawsze uzyska się sensowną odpowiedź. Jest to zawsze model lub zbiór modeli, które zanim osiągną wysoki poziom efektywności w przypisanym im – na ogół bardzo ograniczonym – zakresie działania, muszą być nieraz przez wiele tygodni optymalizowane przez specjalistów doskonale rozumiejących szeroki kontekst, w jakim będą one funkcjonować oraz konkretne cele, jakie mają realizować.
Jak wygląda to w praktyce? Dlaczego i w jaki sposób sztuczna inteligencja zmienia sposób pracy zarówno ludzi wykonujących proste, powtarzalne czynności, jak i wysokiej klasy specjalistów? Wyjaśnię to, jak wspomniałem wcześniej, na przykładzie zwalczania wyłudzeń w handlu internetowym – czyli jednego z kluczowych obszarów działalności Nethone. Wybór ten jest nieprzypadkowy. Nie wynika tylko ze specjalności firmy, w której na co dzień pracuję, ale również z faktu, że właśnie w zwalczaniu wyłudzeń stosowanie uczenia maszynowego przynosi naprawdę spektakularne rezultaty.
Problem: wyłudzenia w handlu online (fraud płatniczy)
Wyłudzenia w handlu internetowym, czyli tzw. fraudy, polegają najczęściej na tym, że oszust dokonuje w sieci zakupów korzystając z kradzionych danych karty płatniczej. Kiedy prawowity posiadacz karty odkrywa, że została obciążona z tytułu transakcji, których nie wykonywał, składa w banku reklamację i zwykle otrzymuje zwrot środków (jest to tzw. chargeback). Ponieważ ktoś musi zapłacić za wyłudzone dobra, w wyniku przejścia reklamacji przez cały łańcuch instytucji zaangażowanych w obsługę płatności, okazuje się na ogół, że obowiązek ten spoczywa na sklepie internetowym, który zaakceptował feralną transakcję.
Traci on de facto trzy razy:
1) gdy zostaje pozbawiony towaru wysłanego oszustowi,
2) gdy zostaje pozbawiony pieniędzy za ten towar (wymóg zwrotu),
3) gdy ponosi koszty proceduralne.
Co więcej, organizacje kartowe nakładają na sprzedających oraz procesorów płatności restrykcyjne limity dopuszczalnych liczby i wartości chargebacków w miesiącu. Przekroczenie takiego limitu skutkować może w najlepszym wypadku karami, a w najgorszym – pozbawieniem możliwości dalszego przyjmowania kart.
Sprzedawcy muszą się zatem skutecznie bronić przed naciągaczami. W jaki sposób? Przede wszystkim nie przyjmując podejrzanych transakcji, a zatem takich, które noszą różnego rodzaju znamiona wskazujące, że dokonuje ich ktoś inny niż osoba, której bank wydał kartę. Jak rozpoznać takie transakcje? To właśnie najtrudniejsze zadanie. Zapobieganie wyłudzeniom online polega na pozyskiwaniu właściwych danych opisujących transakcję, dokonującego jej użytkownika oraz kartę.
W oparciu o wyniki wnikliwej analizy owych danych, podejmowana jest decyzja, czy daną płatność przyjąć, czy może odrzucić. Błędy są tu niemal równie kosztowne jak same wyłudzenia. Jeśli „legalna” transakcja zostanie błędnie uznana za próbę oszustwa i w konsekwencji odrzucona, kupujący najprawdopodobniej odejdzie do konkurencji. Odrzucanie każdej transakcji, która wzbudzi choćby cień wątpliwości, nie jest zatem właściwą drogą, bo hamuje sprzedaż. Krótko mówiąc, skuteczne zwalczanie fraudu wymaga niemal bezbłędnego wykrywania prób wyłudzenia. Dość teorii. Jak w praktyce odbywa się ochrona przed fraudami i co właściwie zmienia w niej sztuczna inteligencja? Zacznijmy od pierwszej części pytania.
Walka z wiatrakami, czyli rozwiązania bez udziału sztucznej inteligencji
Zapobieganie oszustwom należy zwykle do obowiązków managerów ryzyka. Są to osoby posiadające specjalistyczną wiedzę w zakresie sposobu działania przestępców internetowych i handlu online, potrafiące na podstawie własnego doświadczenia, badań i obserwacji zdefiniować desygnaty fraudu. Managerowie ryzyka korzystają z różnego rodzaju oprogramowania do filtrowania transakcji w oparciu o zbiory reguł tworzonych przez nich na podstawie eksperckiego know-how.
Ponieważ sposób działania przestępców stale się zmienia, handel internetowy praktycznie nie zna granic, a skuteczne zarządzanie ryzykiem wymaga doskonałego zrozumienia całej sieci współzależności i uwarunkowań występujących na poszczególnych rynkach, jest ono trudne, kosztowne i w dobie szybkiego rozwoju e-commerce coraz mniej wydajne. Dlaczego? Otóż managerowie ryzyka, chcąc dobrze zabezpieczyć biznes przed oszustami w warunkach wspomnianej złożoności zjawisk, tworzą coraz więcej reguł, zgodnie z którymi transakcje są przyjmowane lub odrzucane. Reguły stają się coraz bardziej skomplikowane i wzajemnie ze sobą powiązane, a co za tym idzie, coraz trudniejsze do szybkiej aktualizacji.
Tymczasem, wystarczy choćby niewielka zmiana w sposobie działania oszustów, by cały zestaw reguł stał się kompletnie nieskuteczny. Konieczna jest wówczas gruntowna przebudowa całej logiki antyfraudowej, co wymaga czasu, wysiłku i pieniędzy.
Wyobraźmy sobie dla przykładu system, w którym działają reguły mówiące, że transakcja wykonywana za pomocą karty kredytowej wydanej w Niemczech przez użytkownika znajdującego się w Argentynie, gdy w Buenos Aires jest noc, powinna zostać odrzucona jako potencjalna próba oszustwa. Po pierwsze, w wyniku działania takiego zestawu, niemiecki turysta zwiedzający Amerykę Łacińską nie dokona zakupu (strata!). Po drugie, jeśli faktycznie tego typu transakcje okazywały się ostatnio w większości wyłudzeniami, wystarczy, że oszust zamiast z argentyńskiego IP, zacznie korzystać np. z adresu hiszpańskiego. Pora dnia w Buenos Aires traci w tym momencie jakiekolwiek znaczenie, a transakcja zostanie przyjęta i poskutkuje chargebackiem. Specjaliści muszą w takiej sytuacji najpierw wykryć zmianę w działaniu oszustów, a następnie zmodyfikować reguły tak, by uwzględniały hiszpańskie adresy IP jako obarczone podwyższonym ryzykiem.
Krótko mówiąc, managerowie ryzyka poświęcają czas i energię na budowanie zestawów reguł i ich ciągłe kompleksowe aktualizowanie, podczas gdy przestępcy potrafią jednym, czasem niewielkim, gestem obrócić cały ich wysiłek wniwecz. Co więcej, aby reguły działały z wysoką dokładnością, muszą bazować na dużych zbiorach danych opisujących każdego użytkownika danego sklepu internetowego. Nie sposób przecież odrzucać transakcje tylko dlatego, że pochodzą z jakiegoś konkretnego kraju lub są dokonywane w określonych godzinach. To by zabiło każdy internetowy biznes kierujący ofertę do klientów z różnych krajów. Konieczne jest zatem pozyskiwanie rzetelnych danych i ich dogłębna analiza. Jedno i drugie stanowi poważne wyzwanie. Od tych problemów rozpocznę też objaśnienie dot. wykorzystywania sztucznej inteligencji w zwalczaniu wyłudzeń.
Sztuczna inteligencja jako odpowiedź
Rozwiązaniem odpowiadającym na opisane powyżej problemy okazuje się być sztuczna inteligencja w połączeniu z wielowymiarowym, głębokim profilowaniem użytkowników. Jak wspomniałem wcześniej, komputery co prawda nie są dziś w stanie wykonywać wszystkich zadań intelektualnych, jakie potrafią wykonać ludzie, jednak pod względem szybkości obliczeń zostawiają nas daleko w tyle. Są w stanie dzięki temu przeanalizować znacznie większe zbiory danych w znacznie krótszym czasie niż człowiek, czy nawet zespół bardzo bystrych ludzi. Trzeba im „tylko” zapewnić dostęp do odpowiednich zbiorów wiarygodnych danych charakteryzujących użytkowników.
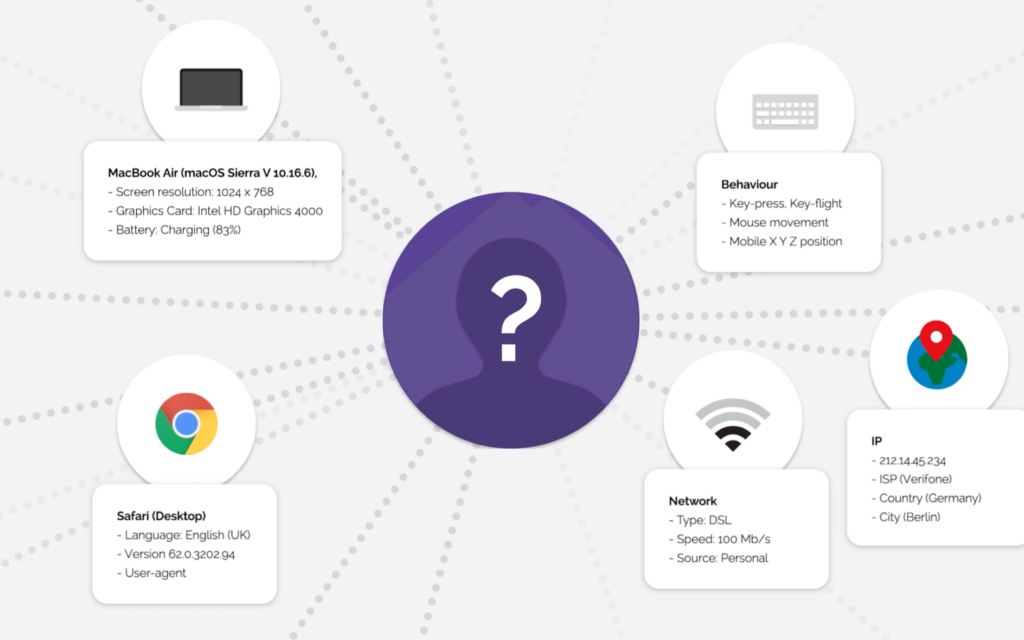
W Nethone stworzyliśmy w tym celu autorskie narzędzie profilujące, które jest w stanie dogłębnie prześwietlić każdego użytkownika serwisu, gromadząc tysiące punktów danych składających się na jego cyfrowy wizerunek. Narzędzie zbiera bogate, rzetelne (trudne do zmanipulowania) informacje dotyczące sprzętu, oprogramowania, otoczenia sieciowego i zachowania użytkownika w interakcji z daną stroną internetową czy aplikacją natywną. Skala naprawdę robi wrażenie.

Przykładowo, jako zachowanie rozumiemy zarówno to „co” użytkownik robi, jak również „w jaki sposób” to robi – jak pisze na klawiaturze wypełniając formularz zamówienia, w jaki sposób porusza myszką, jak przewija treści na ekranie dotykowym, w jakim położeniu trzyma smartfon (jeśli łączy się mobilnie), czy porusza tym smartfonem podczas przeglądania serwisu, czy może trzyma go w stałej, niezmiennej pozycji. Wszystkie te dane łączymy z informacjami, które w danym kontekście mogą okazać się istotne. Jeśli np. mowa o zakupach internetowych w branży turystycznej (głównie bilety lotnicze i rezerwacje hotelowe), uwzględniamy choćby odległość między punktem, w którym znajduje się kupujący dokonując transakcji a portem lotniczym, z którego planuje podróżować. Takich specyficznych dla branży chronionego serwisu zmiennych jest całe mnóstwo.
W sytuacji, kiedy dysponujemy wspomnianym powyżej ogromem danych, pojawia się konieczność ich przeanalizowania. Tutaj po raz pierwszy na scenę wkracza sztuczna inteligencja. Specjalnie stworzone i wytrenowane w tym celu modele uczenia maszynowego są wykorzystywane do drobiazgowej analizy wszystkich zebranych informacji i wykrywania zależności pomiędzy nimi. Dzięki nieosiągalnej dla człowieka szybkości obliczeń, modele są w stanie znaleźć powiązania pomiędzy zmiennymi, które z pozoru nie mają ze sobą nic wspólnego, a w dodatku wielogodzinną pracę człowieka zamykają w ułamku sekundy. Jest to możliwe dzięki odpowiedniemu przygotowaniu modeli przez ekspertów, którzy z jednej strony doskonale rozumieją arkana inżynierii i analizy danych, z drugiej – kontekst techniczny i biznesowy.
Znając zależności i strukturę danych, przechodzimy do kolejnego etapu – czyli predykcji. Tutaj sztuczna inteligencja po raz kolejny okazuje się niezastąpiona. Modele, wytrenowane m.in. na zbiorach danych „zrozumianych” dzięki opisanemu powyżej procesowi, analizują wartość wszystkich zmiennych i samodzielnie udzielają odpowiedzi na pytanie, czy dana transakcja jest próbą wyłudzenia, czy też nie.
Modeli jest oczywiście znacznie więcej, wykorzystywane są do różnych celów w ramach procesu, jednak wspomniane dwa elementy (profilowanie i uczenie maszynowe) mają kluczowe znaczenie dla realizacji zadania, jakim jest trafne wykrycie transakcji dokonywanych przez oszustów.
Analizy, o których wspomniałem, realizowane są niemal w czasie rzeczywistym i w sposób ciągły. Sztuczna inteligencja jest przeuczana wraz z napłynięciem nowych transakcji, aby zachować wysoki poziom trafnych rekomendacji. Jeśli oszuści zmienią sposób działania, modele szybko to wykryją i uwzględnią w prowadzonych analizach. Rola managerów ryzyka zmienia się więc w tym ujęciu w sposób zasadniczy. Przestają oni ręcznie tworzyć filtry, lecz stają się partnerami i nadzorcami sztucznej inteligencji, której odpowiednia wydajność gwarantuje bezpieczeństwo.
Na koniec jeszcze kilka rezultatów w liczbach. Pracując dla jednego z wiodących internetowych serwisów VOD, udało nam się dzięki połączeniu sztucznej inteligencji i głębokiego profilowania użytkowników zredukować liczbę odrzucanych transakcji o 50%, zmniejszając jednocześnie liczbę notowanych chargebacków o 40%.
Opisane przeze mnie case study automatycznie prowokuje pytanie o to, czy modeli nie można by wytrenować pod kątem przewidywania czegoś innego niż fraudy, np. prawdopodobieństwa dokonania zakupu określonego produktu czy ryzyka odejścia do konkurencji. Oczywiście, że można. Tym również się zajmujemy wraz zespołem, jednak to temat na oddzielny artykuł.
Mam nadzieję, że udało mi się sporo wyjaśnić – pokazać jak wielką wartość przynosi sztuczna inteligencja biznesowi, a ewentualny strach czytelnika przed robotami przejmującymi kontrolę nad światem choć trochę przesunąć do sfery emocji kinowych.

Podobne artykuły

Prompt engineering – jak pisać skuteczne prompty do AI

AI Developer – kim jest, ile zarabia i jak nim zostać?

Nowy Frontend: Generative UI i koniec sztywnych layoutów

Fractional CTO / Architect – era ekspertów "na godziny" dla startupów AI

Senior AI Auditor – strażnik etyki i compliance w polskim software house

Local-First Software – nowy standard budowania aplikacji w 2026 roku
Moltbook i agenci AI: 1,5 miliona botów, które miały się "obudzić" – a to był spektakl reżyserowany przez ludzi
