Od czego zacząć poznawanie metodyki DevOps?

Postanowiłem podzielić się podstawami DevOps dla tych, którzy chcą lepiej zapoznać się z tematem i zrozumieć, czym jest metodyka DevOps, jakie są główne koncepcje tego kierunku i jak może być przydatny.
Firmy nieustannie poszukują sposobów na zwiększenie wydajności i obniżenie kosztów. W tym celu stworzono DevOps, metodologię, która pozwala zapewnić szybkość i jakość rozwoju oprogramowania.
Ten artykuł nie odpowie na wszystkie Twoje pytania, a jedynie pomoże Ci powierzchownie zrozumieć temat i być może wzbudzi jeszcze więcej pytań, które pomogą Ci przejść od teorii DevOps do praktyki.
Kolejnym celem jest zwrócenie uwagi programistów, QA i innych specjalistów IT na Docker i to, jak może być on wykorzystywany w pracy. To był niewielki disclaimer, a teraz zacznijmy od podstaw.
Spis treści
Od czego zacząć: kontenery i Docker
Dla celów praktyki DevOps zaleca się zwrócenie uwagi na wykorzystanie kontenerów.

Kontenery są wygodnym narzędziem do wdrażania i uruchamiania oprogramowania na dowolnym urządzeniu lub w dowolnym środowisku. Kontenery pozwalają izolować aplikacje od innych aplikacji systemu operacyjnego (korzystając w szczególności z przestrzeni “namespaces kernel feature”), skrócić czasu wdrażania i dają niezależność od środowiska.
Jes to coś, co pomoże zespołom zacząć korzystać ze wspólnych (standardowych) narzędzi i podejść do koordynowania swojej pracy.
Korzystanie z kontenerów nie jest nowym podejściem. Jeśli zaczniesz googlować na ten temat, dowiesz się, że najpopularniejszą implementacją kontenerów jest Docker. Następnym krokiem będzie zrozumienie, czym jest Docker, jak z niego korzystać i dlaczego warto korzystać właśnie z kontenerów.
Kontenery vs. maszyny wirtualne
Kontenery i maszyny wirtualne (VM) to technologie wirtualizacji, które umożliwiają uruchamianie aplikacji oddzielnie od innych aplikacji i systemu operacyjnego hosta. Istnieją jednak pewne różnice między nimi, które sprawiają, że kontenery są kolejnym krokiem po korzystaniu z maszyn wirtualnych.
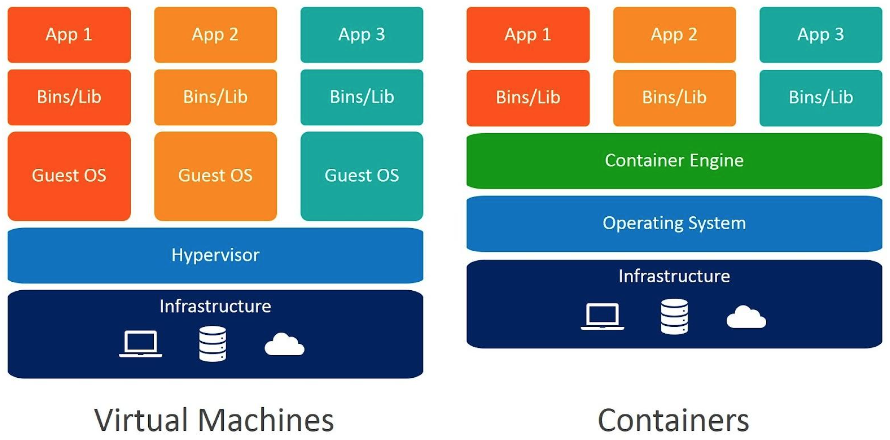
- Maszyna wirtualna wymaga więcej zasobów, ponieważ każda maszyna wirtualna ma własną kopię systemu operacyjnego, podczas gdy kontenery współdzielą system operacyjny z systemem hosta.
- Kontenery są mniej odizolowane niż maszyny wirtualne, więc mogą być mniej bezpieczne, jeśli system hosta ma jakiekolwiek problemy z bezpieczeństwem. Innymi słowy, jeśli system hosta zostanie naruszony, możliwe jest, że kontenery również zostaną naruszone.
- Kontenery są łatwiejsze i szybsze w tworzeniu i wdrażaniu, ponieważ zawierają tylko aplikacje i jej zależności, podczas gdy maszyna wirtualna musi zawierać kompletny system operacyjny.
- Kontenery są zazwyczaj lżejsze i zajmują mniej miejsca na dysku niż maszyny wirtualne.
- Kontenery mają niższy narzut systemowy, co pozwala na ich wykorzystanie do szybszego tworzenia, testowania i wdrażania aplikacji.
Googlując dalej, natrafiamy na jeszcze więcej szczegółów technicznych dotyczących Docker:
To właśnie w tym miejscu wiele osób decyduje, że nie potrzebują Dockera i wracają do starego dobrego lokalnego serwera WWW. I to jest największy problem, który prowadzi do:
- Zachowania podejścia “U mnie lokalnie wszystko działa, a Ty to ogarnij” i braku podejścia, w którym Ty i Twoje środowisko pracy korzystacie z jednego narzędzia.
- Jeśli potrzebujesz uruchomić kilka witryn z różnymi wersjami PHP, MySQL lokalnie, musisz zmienić wersję dla każdej z nich. Uruchomienie tych witryn niezależnie z różnymi charakterystykami jest niemożliwe.
- Jak mogę uruchomić moją aplikację na innym komputerze lub serwerze albo u innego programisty, któremu chcę ją udostępnić? Tutaj zaczynają się utrudnienia.
Dobrą wiadomością jest to, że nie musisz wiedzieć, jak działa Docker, aby zacząć z niego korzystać. Wystarczy, że opanujesz podstawowe operacje, a następnie, jeśli chcesz, pójdziesz głębiej.
Drugą dobrą wiadomością jest to, że uruchomienie Docker w systemie Windows nie wymaga wiele wysiłku. Wystarczy pobrać Docker Desktop i wybrać opcję korzystania z WSL2 podczas instalacji, która umożliwia uruchamianie natywnych aplikacji linuksowych w systemie Windows.
Jako przykład uruchommy lokalny serwer WWW nginx. W tym celu musimy określić w Docker Desktop, co dokładnie chcemy uruchomić. Tworzymy folder, na przykład „nginx”, a w nim plik o nazwie „compose-dev.yaml” z następującą zawartością:
Pod dyrektywą services wymieniamy kontenery, które chcemy uruchomić. Ich nazwy mogą być dowolne, ale logicznym będzie nazwanie usług zgodnie z ich przeznaczeniem. W tym przypadku mamy tylko jeden kontener — nginx. Kontener ten musi być uruchamiany z obrazu nginx (image: nginx). Warto wiedzieć, że nazwa obrazu jest określona w postaci repository/image:tag, gdzie repository jest lokalizacją, z której Docker pobiera obraz, a tag jest wersją obrazu.
Jeśli repository і tag zostaną pominięte, oznacza to, że obraz zostanie pobrany z najnowszej wersji i ściągnięty z DockerHub, najpopularniejszego serwisu do przechowywania obrazów. Wspomnijmy tutaj o jeszcze jednej dyrektywie — ports. Pozwala ona na dostęp do portów kontenera (które działają we własnej sieci) poprzez porty na lokalnym urządzeniu (localhost). Po lewej stronie znajduje się port na lokalnym urządzeniu, po prawej port kontenera. W ten sposób na adres http://localhost:8080 odpowie proces kontenera nasłuchujący na porcie 80, czyli serwer WWW.
W pliku może być o wiele więcej dyrektyw, pełną listę można znaleźć w pliku Compose file version 3 reference.
Ten plik jest wszystkim, czego potrzebujesz do uruchomienia nginx. Otwórz Docker Desktop, wybierz Dev Environments i utwórz nowe środowisko.
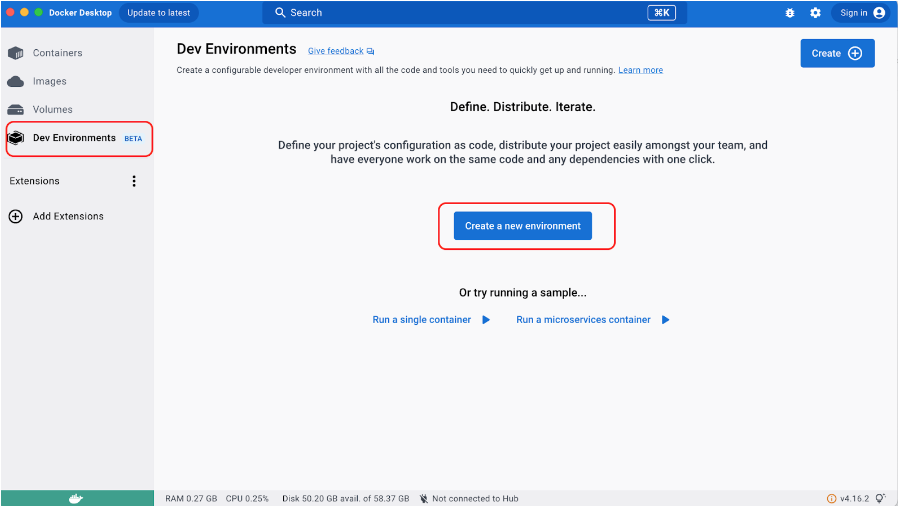
W sekcji „Choose source” wybierz „Local directory” i określ katalog, w którym został utworzony plik „compose-dev.yaml”.
Docker Desktop pobierze najnowszy obraz nginx z DockerHub (lub znajdzie obraz na Twoim komputerze, jeśli został pobrany wcześniej) i na jego podstawie uruchomi kontener.
Po kliknięciu na uruchomiony kontener możesz zobaczyć jego logi. Ich aktualizacja odbywa się w czasie rzeczywistym, więc jeśli na przykład spróbujemy otworzyć nieistniejącą ścieżkę (http://localhost:8080/nosuchpath), fakt ten zostanie natychmiast odzwierciedlony w logu nginx:
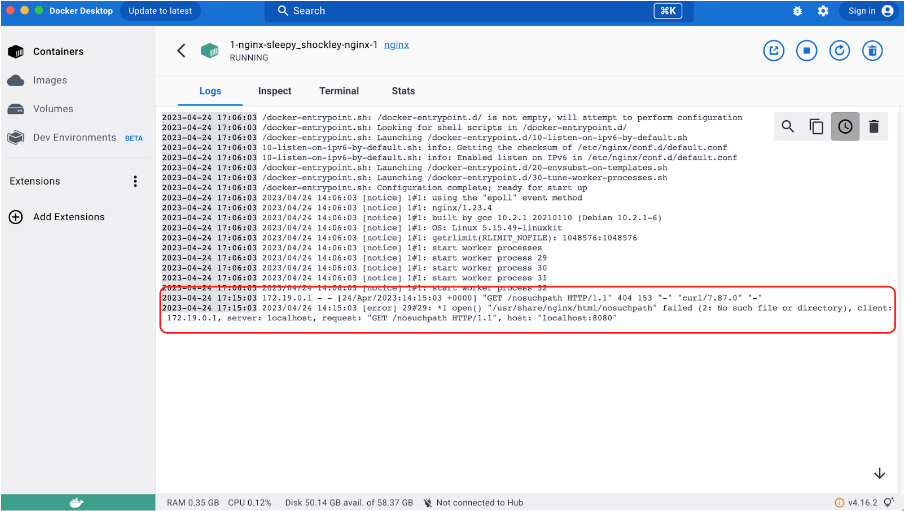
Nawiasem mówiąc, gdy kontenery działają nie na urządzeniu programisty, ale w środowisku roboczym, demonstracyjnym lub produkcyjnym, ich logi są zwykle zbierane przez inne kontenery i wysyłane do specjalnych baz danych, co umożliwia przeglądanie, wyszukiwanie i powiadamianie na podstawie określonych komunikatów w logach.
Spróbujmy teraz uruchomić nieco bardziej złożony przykład. Dla uproszczenia usuńmy obecne środowisko programistyczne i utwórzmy nowe w oparciu o inny plik „compose-dev.yaml”:
Ten plik pochodzi z DockerHub WordPress i został nieznacznie zmodyfikowany: ROOT_PASSWORD = 1 i używana jest najnowsza wersja MySQL.
Oczywiście nie zaleca sią przechowywanie loginów i haseł w postaci zwykłego tekstu. Te rzeczy zwykle są przechowywane w specjalnych miejscach do przechowywania wrażliwych danych (np. zmienne Gitlab CI/CD, Hashicorp Vault itp.) i używane podczas wdrażania. Wrażliwe dane powinny być przynajmniej umieszczone w osobnym pliku, co pokażemy później, ale na razie zostawmy to.
Sam plik ma kilka komplikacji w porównaniu do pierwszego:
- Dodano dyrektywę depends_on, aby uruchomić WordPress po MySQL. W tym przypadku Docker nie będzie czekał, aż MySQL zostanie w pełni uruchomiony, po prostu uruchomi najpierw jeden kontener, a następnie drugi;
- Poświadczenia (credentials) MySQL root i jeszcze jednego użytkownika, a także bazy danych, są określone w postaci zmiennych środowiskowych. Oczywiste jest, że te same bazy danych, nazwy użytkowników i hasła muszą być określone dla obu kontenerów, różnią się tylko nazwy zmiennych. Użyte zmienne są opisane w DockerHub WordPress;
- Dodano volumes. Umożliwiają one przechowywanie niektórych plików poza kontenerem, wystarczy je tam zmapować. Bez nich wszystkie zmiany wewnątrz kontenerów zostaną utracone. Tak właśnie działają kontenery — domyślnie nie zapisują wprowadzonych w nich zmian. A tutaj mówimy, że wszystko, co zmieni sią w plikach WordPress i bazie danych MySQL w czasie działania kontenerów, zostanie zapisane nawet po ich zatrzymaniu/ponownym uruchomieniu.
Ważną kwestią jest to, że ścieżka do hosta mysql jest określona jako WORDPRESS_DB_HOST=mysql. Mysql to nazwa usługi mysql w pliku compose-dev.yaml.
Gdyby usługa nazywała się db, należałoby zmienić zarówno WORDPRESS_DB_HOST, jak i depends_on na db.
Teraz uruchommy Dev Environment na podstawie nowego pliku. Po otwarciu http://localhost:8080 zobaczymy okno inicjalizacji WordPress:
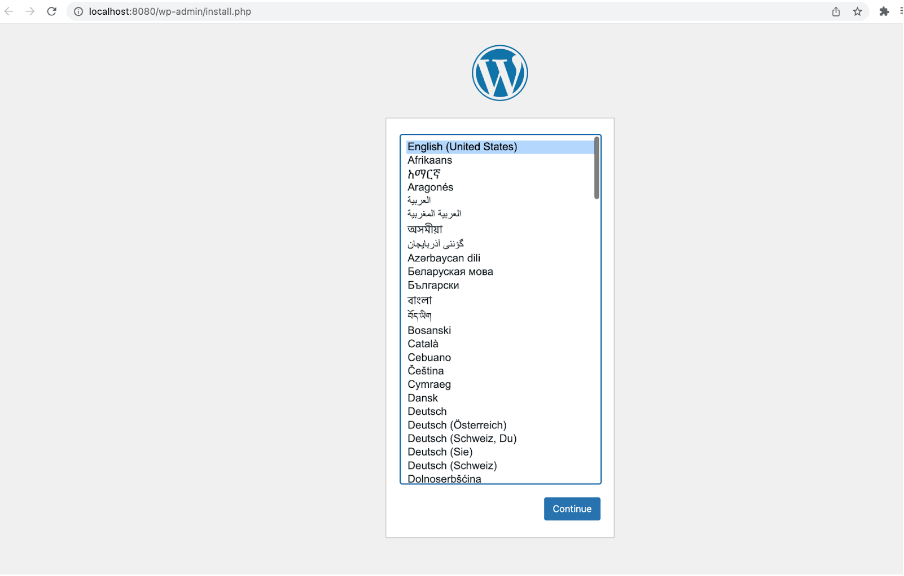
Zainicjujmy WordPress, wprowadzając wymagane dane, w tym login i hasło do panelu administracyjnego. Zmieniając coś w sekcji Pages, a następnie ponownie uruchamiając kontener ze środowiska programistycznego, możesz upewnić się, że zmiany zostały zapisane.
Skomplikujmy odrobinę ten przykład: umieszczamy wszystkie poświadczenia w osobnym pliku i dodajemy kontener z phpMyAdmin. Kilka Dev Environments może istnieć obok siebie, ale port 8080 może być zajęty tylko przez jedno z nich, dla reszty należy zmienić port localhost.
Dla uproszczenia usuniemy bieżące środowisko i utworzymy nowe przy użyciu konfiguracji compose-dev.yaml:
Widzimy, że został dodany kontener phpMyAdmin, a zmienne środowiskowe są odczytywane z pliku local.env w następujący sposób:
Pamiętaj, że nie musisz przechowywać takiego pliku w repozytorium, możesz go nawet dodać do .gitignore., dzięki czemu będzie on odczytywany lokalnie i generowany automatycznie z Secrets w Gitlab podczas wdrażania.
Po uruchomieniu Dev Environments i zainicjowaniu WordPress pod adresem http://localhost:8080, w konsoli phpMyAdmin pod adresem http://localhost:8081 możesz zobaczyć bazę danych i tabele WordPressa:
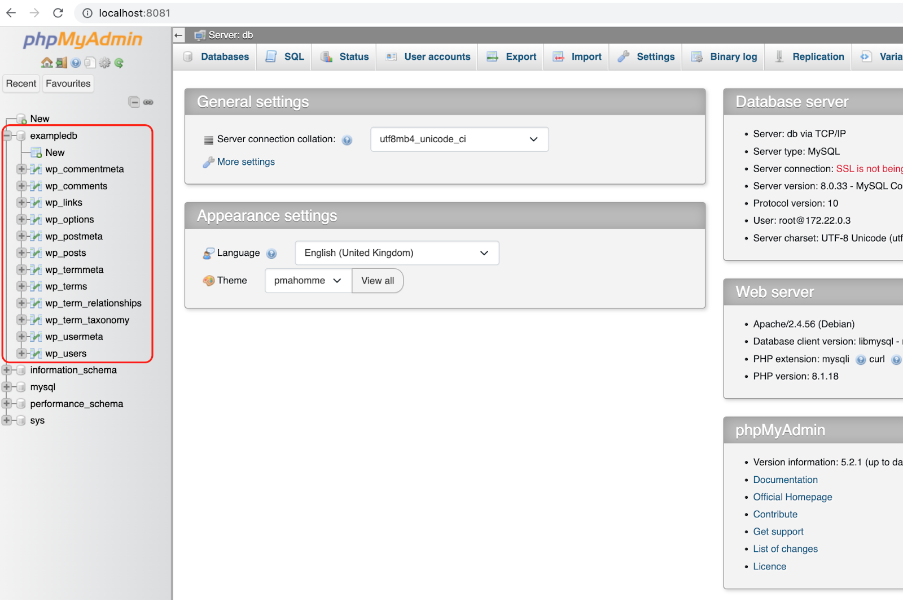
W powyższych przykładach użyliśmy domyślnego WordPress dostępnego po wyjęciu z pudełka (z obrazka), ale chcielibyśmy mieć własny, spersonalizowany, a nawet móc go zmienić.
Pobieramy WordPress ze strony i tworzymy osobny folder, powiedzmy demo-wordpress. Następnie rozpakowujemy do niego archiwum WordPress i zmieniamy coś w folderze wordpress/, na przykład usuwamy domyślne wtyczki z wordpress/wp-content/plugins i dodajemy classic-editor.
compose-dev.yaml użyjemy tego samego, tylko z dwiema małymi zmianami:
- Usuniemy użycie volumes z wordpress-container, usuwając sekcję volumes.
- Jako obraz dla wordpress, podajemy swój własny obraz, mywordpress:v1.
Dlaczego mywordpress:v1 i czym się różni od zwykłego obrazu wordpress? Jego nazwa jest dowolna, podobnie jak wersja, wskazane jest tylko, aby nazwa obrazu w jakiś sposób odpowiadała znajdującej się w nim aplikacji. Od standardowego różni się tym, że katalog /var/www/html jest zastąpiony naszym, z wtyczką, którą dostosowaliśmy powyżej.
Jak zatem uzyskać taki obraz? To proste. Tworzymy plik o nazwie Dockerfile:
Tajemnicze słowa FROM і COPY mają jasne znaczenie — otrzymujemy nasz obraz z obrazu wordpress, kopiując masz lokalny folder wordpress/ do obrazu /var/www/html.
Upewnij się, że zawartość folderu demo-wordpress wygląda następująco:
Po opisaniu tego, co należy zrobić, wykonujemy to (kropka na końcu jest obowiązkowa).
Teraz, jeśli utworzysz nowe Dev Environment, będzie używany utworzony przez Ciebie obraz wordpress.
Ok, nauczyliśmy się budować nasze obrazy lokalnie, ale byłoby super, gdyby ten sam obraz był dostępny w środowiskach demo, staging i production. Innymi słowy, musimy upewnić się, że kiedy wypychamy zmiany do repozytorium, obraz, który zbudowaliśmy lokalnie za pomocą polecenia docker build, jest również budowany zdalnie, podczas procedury budowania i wdrażania na serwerze.
Załóżmy, że nasze repozytorium jest przechowywane na Gitlab. Aby wyjaśnić Gitlab, co należy zrobić po wypchnięciu do repozytorium, należy otworzyć plik YAML o nazwie .gitlab-ci.yml i następującej strukturze:
W skrócie, deklarujemy etapy kompilacji w sekcji stages i przypisujemy zadania (jobs) do każdego etapu. Konkretne kroki każdego zadania są opisane w sekcji scripts.
Prosty przykład .gitlab-ci.yml:
Po wypchnięciu zmian do repozytorium pipeline przywita się z nami.
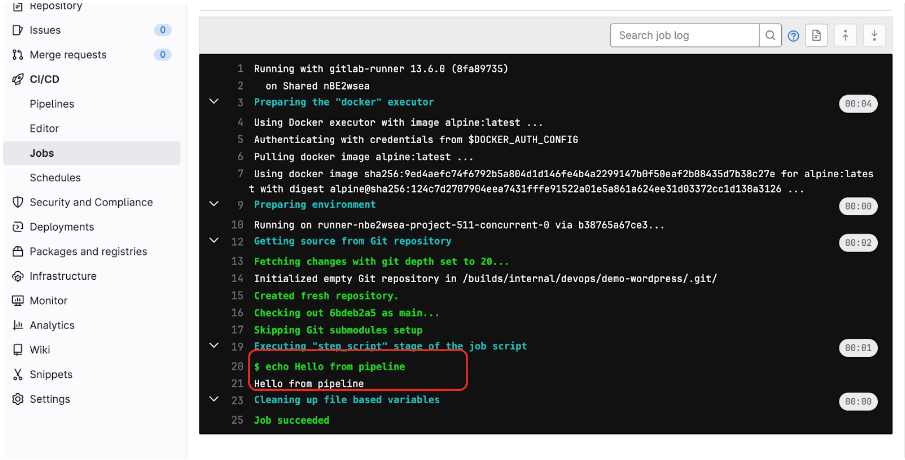
Tym razem nie będziemy przyglądać się urządzeniu CI/CD, czytnikom itp., ale zademonstrujemy proces budowania obrazu, który został opisany powyżej.
Plik roboczy .gitlab-ci.yml dla kompilacji wygląda następująco:
Bez wchodzenia w szczegóły, oto polecenie docker build (poniżej), które buduje obraz, a następnie wypycha go do repozytorium Gitlab, skąd można go pobrać do dalszego wdrożenia. Niestety długość tego artykułu nie pozwala na opisanie wdrażania. Inne nowe elementy (image, services, variables) są potrzebne, aby umożliwić zbudowanie obrazu.
Metodyka DevOps – podsumowanie
Mam nadzieję, że ten krótki przewodnik z podstawowymi informacjami będzie dla Ciebie przydatny i że zrozumiałeś, czym jest DevOps i dlaczego jest ważny dla firm. Świetnie też, jeśli zainteresowałeś się choć trochę korzystaniem z Docker i kontenerów, ponieważ może to nie tylko pomóc w pracy ze wspólnym narzędziem, ale także poprawić jakość komunikacji między programistami, QA i administratorami.
Zdjęcie główne artykułu pochodzi z envato.com.
Podobne artykuły

Maszyny wirtualne – jak zautomatyzować ich użycie?

Erlang spisuje się nie tylko w fazie prototypowania. Historia Michała Zajda
Pisz współbieżne programy, które działają do końca świata. Historia Elixira
