Czas na nowe hobby. Wypróbuj możliwości FPGA w środowisku Python

W obecnych czasach, gdy rozwój platform software’owych i hardware’owych sukcesywnie idzie do przodu, warto nie zamykać się w jednej technologii. Okazuje się bowiem, że rozwój w informatyce nie kończy się na nowych frameworkach i coraz większej mocy przetwarzania. Technologie, które kiedyś były dostępne tylko dla specjalistów, powoli otrzymują kolejne warstwy abstrakcji umożliwiających zastosowanie ich w nowych kontekstach. Dodatkowo obniża się próg wejścia w daną dziedzinę, z punktu widzenia posiadanej wiedzy. Przeczytaj o możliwościach FPGA!
Spis treści
Poznajcie Arduino
Jednym z przykładów takich platform sprzętowo-programowych jest np. Arduino, które stało się mostem łączącym elektronikę z programowaniem w dość prosty i szybki sposób.
Elektronik, decydując się na użycie mikrokontrolera ATmega328p w swoim projekcie wie, że można zaprogramować go np. w języku C/Assembler, a w nocie katalogowej znajdują się opisy wszystkich rejestrów sprzętowych. Programista, używając Arduino, które w podstawowej wersji również bazuje na mikrokontrolerze ATmega328p, ma do dyspozycji obiektowy framework ze sporą ilością przykładów. Finalnie, bez wiedzy z zakresu elektroniki, jest w stanie uruchomić swój program na mikrokontrolerze. Co więcej, za pomocą nakładek rozszerzających funkcjonalność, może np. połączyć się z domową siecią wi-fi i zaimplementować prosty serwer HTTP. Dlatego też na platformy podobne do Arduino, niektórzy stosują określenie: „hardware for software people”.
W ostatniej dekadzie nie tylko małe platformy (w sensie mocy obliczeniowej) zyskały nowe rzesze użytkowników. Raspberry PI jest tutaj świetnym przykładem i na pewno w niejednym inteligentnym domu, spełnia swoją funkcję dostarczając moc obliczeniową na bazie architektury ARM w ramach IoT.
Oczywiście, do dyspozycji pozostają inne platformy oraz ich klony, które będą spełniać dedykowane zadania dużo lepiej niż Arduino lub Raspberry PI. Podobnie jak w przykładzie elektronik kontra programista, celem jest podkreślenie istoty samego trendu a nie konkretnych rozwiązań. Świat elektroniki-informatyki – w zasadzie można już chyba użyć jednego skrótu “IT”- nie kończy się na mikrokontrolerach i procesorach x86/ARM (celowo tutaj generalizuję), a w miarę odkrywania nowych warstw, robi się coraz ciekawiej.
Niedawno powróciłem do nieco zapomnianego przeze mnie hobby – programowania układów FPGA. Posiadając parę starszych płytek, których programowanie i debugowanie momentami kwalifikuje się do sportów ekstremalnych, postanowiłem zweryfikować, co aktualnie oferuje rynek i z pomocą której platformy mogę zredukować wskaźnik „time to market” do minimum. Paradoksalnie, to właśnie w projektach hobbystycznych czas jest cenniejszy, bo jest go znacznie mniej do dyspozycji.
Znalazłem coś niezwykle intrygującego, nie tylko dla elektroników, programistów C/C++, ale również dla programistów języka Python, do których od wielu lat również się zaliczam. Mowa tutaj o płytce prototypowej: Digilent PYNQ-Z1 Python Productivity Board, która zawiera w sobie procesor ARM zintegrowany z układem FPGA oraz szereg wejść/wyjść również kompatybilnych z nakładkami-rozszerzeniami platformy Arduino. Wisienką na torcie jest framework PYNQ, który dodaje przyjazną warstwę abstrakcji w języku Python i otwiera drogę do użycia układów FPGA w pythonowych projektach!

Poniższe opisy/wnioski/przykłady/preferencje wynikają z moich osobistych doświadczeń w programowaniu układów FPGA, które jest jednym z moich hobby.
Czym są układy FPGA?
Układ FPGA to taki „mikrokontroler z plasteliny”, niezwykle plastyczny dzięki budowie opierającej się na konfigurowalnej macierzy połączeń bramek logicznych. Dla kontrastu mikrokontroler obecny w Arduino (ATmega328p) posiada wydzielone bloki w swojej strukturze, które również (upraszczając) składają się z bramek logicznych i dostarczają określone funkcjonalności. Ilość, rozmieszczenie oraz funkcjonalność tych bloków jest stała, co przekłada się na ograniczenia całego mikrokontrolera.
W układzie FPGA, bloki funkcjonalności tworzy się poprzez konfiguracje macierzy połączeń. FPGA to taki efemeryczny mikrokontroler, który dopiero po skonfigurowaniu materializuje swą sprzętową funkcjonalność. Możliwości koncepcyjne są dość niezwykłe, ponieważ za pomocą układu FPGA, który posiada odpowiednio dużą macierz połączeń, można zaimplementować cały procesor. Tak, można „napisać” procesor, budując poszczególne jego bloki w języku „opisu sprzętu”, następnie skonfigurować macierz połączeń w układzie FPGA i od tej pory używać FPGA jako CPU! Wyobraźmy sobie, że w przyszłości, domowe komputery mogłyby być w pełni rekonfigurowalne, a użytkownicy „ściągali” by CPU z internetu. Tak już się dzieje w przypadku otwartej architektury RISC-V, polecam poświęcić 15 minut na niewielki research.
Gdzie występują układy FPGA?
FPGA cieszy się dużą popularnością w fazie prototypowania, niekiedy też producenci decydują się na produkcję urządzeń, w których najważniejsze funkcjonalności dostarczane są za pomocą FPGA. Nie tylko bugfixing całego urządzenia jest prostszy, ale również pozwala ograniczyć dodatkowe funkcjonalności sprzętowe za pomocą licencji. Dobrym przykładem są tutaj np. oscyloskopy, często producenci ze względów ekonomicznych stosują te same płyty główne w najniższej i średniej klasie urządzeń, ograniczając możliwości sprzętowe (np. maksymalne pasmo przetwarzania) za pomocą odpowiedniej konfiguracji układów FPGA z poziomu firmware.
Wszędzie tam, gdzie liczy się czas przetwarzania, FPGA jest jednym z rozsądnych wyborów.

Układy FPGA są używane nie tylko w produktach konsumenckich. Osobną gałąź zastosowania stanowią karty akceleratorów np. na złączach PCI-E, instalowane w centrum danych, które komunikując się z systemem operacyjnym, dostarczają dedykowanych funkcjonalności biznesowych w ramach większego ekosystemu. Chmurom również nie brakuje plastyczności, usługa “FPGA as a service” jest dostarczana przez większych graczy, również w domenie uczenia maszynowego, w których układy FPGA zyskują coraz większe zastosowanie.
Czy jest coś lepszego niż FPGA?
Układy FPGA, przez swoją plastyczność, dodają narzut w produktach końcowych. Mogą zużywać nieco więcej prądu niż ich nie-plastyczne odpowiedniki, koszty produkcji również są większe, lecz wszystko zależy od ilości i zastosowania danego układu. Dla przykładu, w oscyloskopie, który sam w sobie jest już drogim (ale bardzo funkcjonalnym) urządzeniem, wybór FPGA jest uzasadniony. Natomiast w masowo sprzedawanym produkcie, który dostarcza stricte określone funkcjonalności, które nie podlegają zmianom z czasem, lepszym rozwiązaniem byłby układ ASIC.
ASIC jest „zamrożonym w czasie” układem FPGA z wgraną konfiguracją. Porównując FPGA do plasteliny, ASIC jest modeliną, która po procesie utwardzenia otrzymuje stały kształt. Układy ASIC, dzięki usunięciu plastyczności, zużywają mniej prądu i są tańsze w przypadku masowej produkcji.
Istnieją firmy, które oferują „utwardzenie” projektów FPGA do postaci ASIC. Oznacza to, że można napisać swój efemeryczny CPU, następnie zmaterializować go za pomocą FPGA, dodać np. własne peryferia a w przypadku poprawnego działania, zamówić fizyczny mikrokontroler typu ASIC na bazie własnego projektu.

Programowanie
Od strony technicznej, układy FPGA można konfigurować, nie programować, zwykle trwałość konfiguracji ogranicza się do pierwszego zaniku zasilania, gdy komórki pamięci przechowujące macierz połączeń zostaną wyczyszczone. W większości przypadków na płytach urządzeń znaleźć można dodatkowe pamięci flash oraz specjalne układy pomocnicze, które konfigurują docelowo FPGA na starcie. Oznacza to, że konfiguracja wgrywana jest na trwałą pamięć flash, a następnie za pomocą układu pomocniczego sczytywana i przenoszona do docelowego układu. Mniej przyjazne płytki prototypowe, nie posiadają układów pomocniczych. W przypadku urządzeń nieco bardziej skomplikowanych np. oscyloskop / internetowy modem kablowy konfiguracją FPGA może zarządzać główny procesor.
Współbieżność
Plastyczność FPGA umożliwia duplikację bloków funkcjonalności, nawet wielokrotną, wszystko zależy od pojemności danego układu. Duplikacja funkcjonalności oznacza duplikację fragmentu konfiguracji macierzy połączeń, nowe połączenia tworzące blok, będą fizycznie zrealizowane w innym miejscu układu. Oznacza to, że skopiowany blok może działać niezależnie od swojego oryginału.
W komputerach PC z jednordzeniowym procesorem, wrażenie współbieżności zostało uzyskane za pomocą schedulera, który zarządza czasem procesora. Scheduler udostępnia CPU uruchomionym programom na określony czas, samo przełączenie czasu procesora jest bardzo szybkie i użytkownik odnosi wrażenie, że programy pracują równolegle. W teorii, gdyby drastycznie obniżyć taktowanie CPU oraz odpowiednio wydłużyć okresy schedulera, dla niektórych programów byłoby możliwe zaobserwowanie przełączania gołym okiem.
Wracając do układu FPGA, (upraszczając) posiada on lepszą współbieżność niż procesor jednordzeniowy, ponieważ przetwarzanie zduplikowanego bloku funkcjonalności odbywa się fizycznie w innej części układu. W przypadku jednordzeniowych procesorów komputerów PC, skopiowany program, uruchomiony „równolegle” do oryginału, musi oczekiwać na swój czas procesora, więc jest to pozorna współbieżność.
ZYNQ-7000 SoC czyli System On a Chip
W ostatnich latach popularność układów SoC znacząco wzrosła, również w konsumenckim segmencie rynku. Apple zostawiło nieco w tyle konkurencję za pomocą ich pierwszego procesora architektury ARM – M1, który również jest układem typu System On a Chip i cieszy niebywałą wydajnością.
System On a Chip, najprościej mówiąc, to przeniesienie niektórych funkcjonalności płyty głównej do pojedynczego układu. Taka integracja oczywiście ogranicza możliwość rozbudowy lub wymiany komponentów urządzenia, lecz zwykle idzie w parze z dużym wzrostem wydajności całej jednostki, jednocześnie zużywając mniej energii.
Układ ZYNQ-7000, który jest sercem płytki prototypowej PYNQ-Z1, jest również układem typu SoC. W tym przypadku architektura ARM oraz układ FPGA zostały zamknięte w jednej obudowie i połączone ze sobą liniami pamięci oraz sterowania, wisienką na torcie jest możliwość współdzielenia pamięci RAM, czyli odpada narzut z kopiowania danych do/z układu FPGA. W skrócie wystarczy zaalokować ciągły blok pamięci z poziomu programu/systemu operacyjnego i przekazać jego adres do układu FPGA, taka pamięć może być dostępna zarówno do odczytu, jak i zapisu.
Wybór algorytmu do akceleracji
Do porównania działania algorytmu na procesorze ARM oraz układzie FPGA, posłuży popularny algorytm haszujący SHA-1. Jest on na tyle złożony obliczeniowo, że różnica w czasie wykonania powinna być zauważalna. Dodatkowo, sam układ ZYNQ-7000 posiada instrukcje CPU używane przez biblioteki kryptograficzne do akceleracji algorytmów haszujących. Uruchomienie SHA-1 na CPU za pomocą tych bibliotek, finalnie będzie najwydajniejsze. Porównanie czasu wykonania obejmie więc trywialną implementację algorytmu bez pełnego wsparcia CPU, tak jakby to miało miejsce w przypadku szybkiego prototypownia dedykowanych algorytmów.
Akceleracja w środowisku Python
Framework PYNQ umożliwia konfigurowanie, wymianę danych oraz start/reset skonfigurowanych bloków funkcjonalności FPGA. Nie oznacza to jednak, że kod z języka Python można użyć bezpośrednio na samym układzie. W tym przypadku należy posłużyć się implementacją w C lub C++, następnie za pomocą IDE XIlinx Vitis HLS dokonać translacji z kodu C/C++ na blok funkcjonalności zrozumiały dla układu FPGA zany RTL (Register Transfer Level). Wygenerowany blok następnie należy podłączyć do procesora ZYNQ-7000 w IDE Xilinx Vivado. Pierwszą część, można napisać samemu bezpośrednio w języku VHDL lub Verilog, pomijając syntezę kodu C/C++ za pomocą Vitis HLS (High Level Synthesis).
Ekosystem Xilinx jest dość rozbudowany, w sieci internet znajduje się duża ilość materiałów instruktażowych i dokumentacji, dlatego też poniższy opis skupi się bardziej na funkcjonalnej stronie zadania.
Na potrzeby dalszej części artykułu, SHA-1 będzie określany jako „algorytm”, aby podkreślić, że celem nie jest implementacja SHA-1 na FPGA, tylko akceleracja złożonego obliczeniowo algorytmu, który można uruchomić ze środowiska Python.
Algorytm w języku C
Kod algorytmu został napisany w języku C w taki sposób, aby można było go uruchomić po kompilacji na procesorze ARM, oraz użyć tej samej postaci do syntezy RTL. Pliki źródłowe zawierają dodatkowe dyrektywy preprocesora dedykowane dla syntezy RTL Xilinx Vitis HLS. Kompilator C uruchamiany na ARM/x86 zignoruje nieznane dyrektywy.
Źródła znajdują się tutaj: github.com/aiicore/justjoin.it/blog, do testowej implementacji w C, posłóżył pseudokod z Wikipedii: https://pl.wikipedia.org/wiki/SHA-1.
Synteza algorytmu z C do RTL
Postać RTL (Register Transfer Level) jest abstrakcją opisu układu cyfrowego. Oznacza to, że dokonując syntezy algorytmu z języka wysokiego poziomu (C/C++) na RTL, w zasadzie zmieniamy kod programu na układ elektroniczny. Przemiana kodu programu na “sprzęt” brzmi dość niezwykle, sam proces nie jest tak widowiskowy, wystarczy skonfigurować projekt w Xilinx Vitis HLS i dokonać syntezy, a następnie wyeksportować jako paczkę abstrakcji RTL.
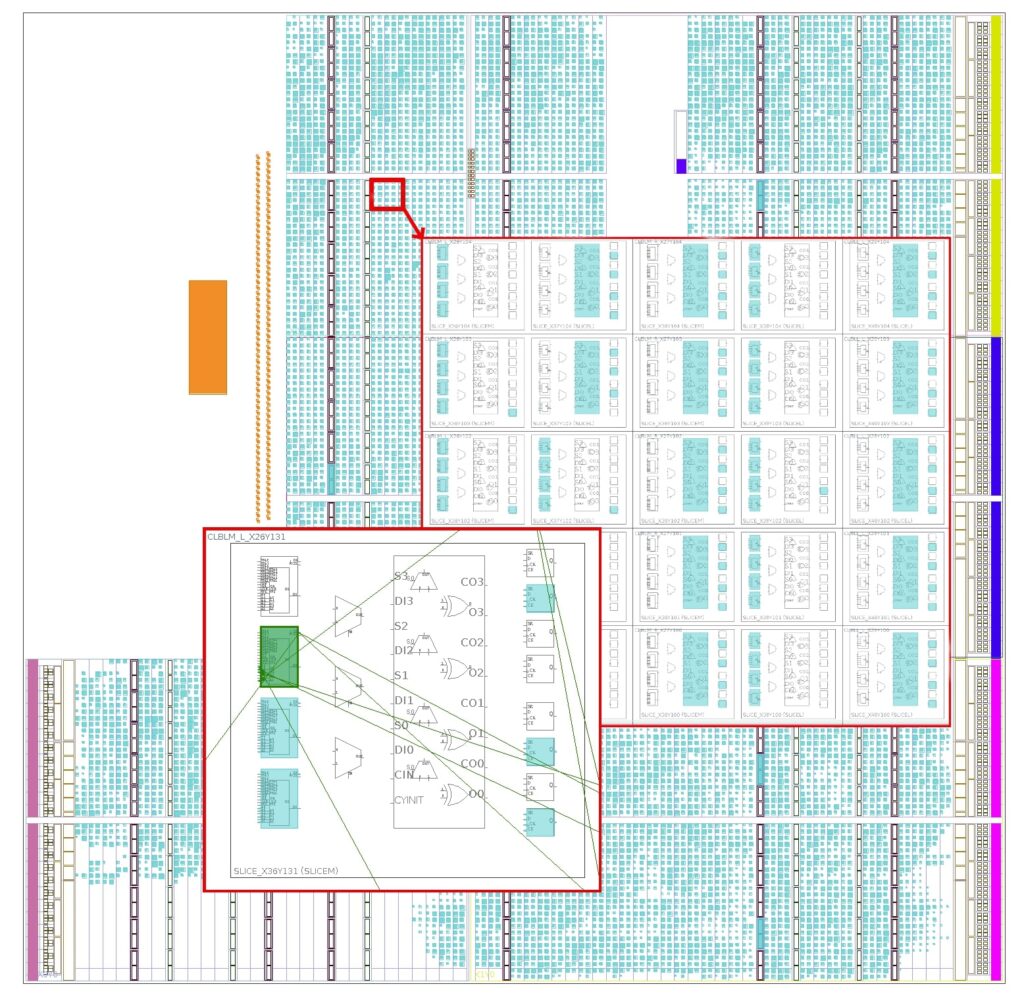
Istotną rzeczą, przy konwersji kodu programu na układ cyfrowy, są właściwości fizyczne danego urządzenia. Gdy kod jest syntetyzowany w formie abstrakcji układu cyfrowego, nagle istotne znaczenie zaczyna mieć prędkość przesyłania sygnałów elektrycznych w układzie FPGA. Im większa żądana prędkość przetwarzania, tym połączenia między elementami układu powinny być krótsze. Dlatego też, podczas syntezy RTL należy ustawić oczekiwaną częstotliwość zegara (lub okres), z jakim blok układu FPGA będzie pracował. Jeśli synteza się uda, jest duża szansa, że konfiguracja i działanie FPGA przebiegnie poprawnie.
Czasem na płytach głównych urządzeń, które pracują z wysokimi częstotliwościami, można dostrzec, że niektóre ścieżki wyglądają jak szlaczki, jakby były specjalnie wydłużone. Tak w świecie fizycznym, wygląda kompensacja czasu przesyłania sygnałów po ścieżce PCB. Podczas syntezy RTL (Xilinx Vitis HLS) oraz routingu (Xilinx Vivado), zachodzi zbliżony proces, ponieważ skonfigurowane połączenia w układzie FPGA, podlegają tym samym prawom fizyki. Matryca konfiguracji nie może zmienić długości ścieżek między blokami funkcjonalnymi, jednakże jednolitość bloków oraz sposób połączenia w matrycy, pozwalają na wiele kombinacji połączeń, tak aby otrzymać założony cykl zegara. Odpowiada za to m.in. proces routingu połączeń uruchamiany w Xilinx Vivado.

Wygenerowany pakiet RTL podchodzi pod szersze nazewnictwo – IP Core (Intellectual Property Core). W środowiskach IDE, oraz w sieci internet dostępne są spore ilości gotowych bloków przetwarzania (IP Core), które można używać za darmo, lub z wymaganą licencją. Nie trzeba zawsze wszystkiego syntezować od zera. Użyteczność IP Core, można porównać do np. bibliotek w danym języku programowania, wystarczy doinstalować i użyć.
Wygenerowanie konfiguracji FPGA
Konfiguracja układu FPGA, czyli wygenerowanie bitstream-u, jest ostatnim krokiem w procesie używania narzędzi Xilinx. Aby do niego dojść (w przypadku ZYNQ-7000), należy zbudować design połączeń bloków RTL z FPGA do procesora.
Układ ZYNQ, jest układem typu SoC (System On a Chip), w którego strukturze znajduje się rdzeń ARM oraz układ FPGA. Design połączeń definiuje, przez jakie interfejsy odbywa się komunikacja z jednego układu do drugiego, oraz w jaki sposób np. spięte są sygnały resetu do bloków układów funkcjonalnych skonfigurowanych w części FPGA.
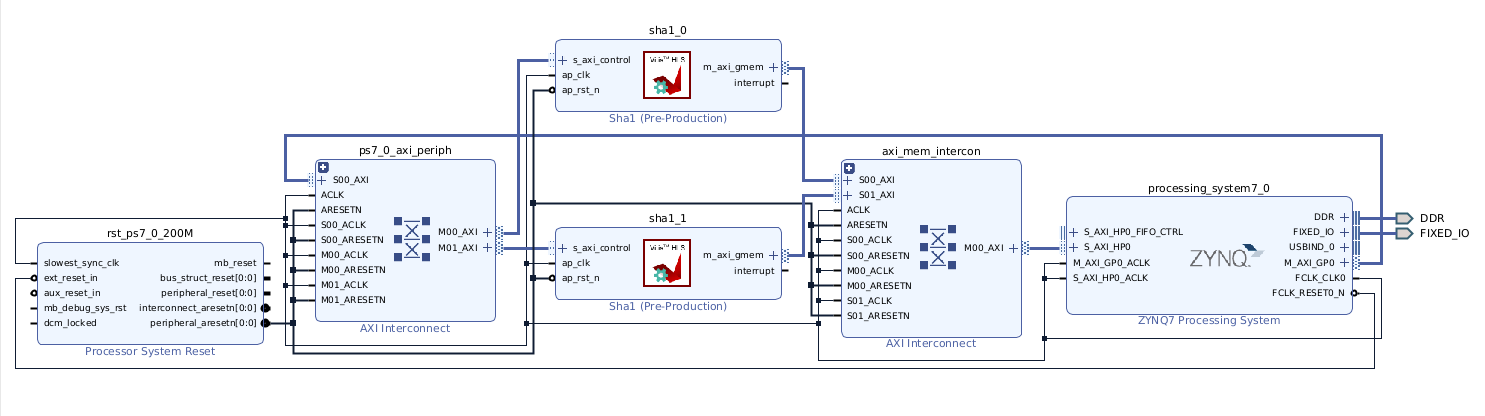
Wygenerowany blok funkcjonalności algorytmu języka C, zamknięty w abstrakcji układu scalonego (RTL) okazał się na tyle mały, że wystarczyło miejsca na umieszczenie kolejnego takiego samego bloku w designie połączeń. Jest to spory sukces, ponieważ z poziomu języka Python, będą dostępne dwa niezależne rdzenie algorytmu, mogące pracować w pełni współbieżnie!
Gdy wszystkie kroki, łącznie z wygenerowaniem konfiguracji – bitstream-u, przebiegną pomyślnie, można przejść do wgrania konfiguracji na układ FPGA oraz uruchomienie samego algorytmu, z poziomu języka Python.
Uruchomienie algorytmu C na procesorze ARM
Aby dokonać najprostszego i w miarę sensownego pomiaru czasu wykonania algorytmu, należy użyć odpowiedniej ilości (długości) danych. Dla niewielkiej ilości danych pomiar byłby zbyt niepewny. Na potrzeby testu użyty został ciągły blok pamięci o rozmiarze 31457280 bajtów (30 MB), wypełniony zerami. Rodzaj danych nie wpływa na długość wykonania zaimplementowanego algorytmu – dla różnych danych, lecz o tej samej ilości (długości) czas wykonania powinien być stały.
Powyższy wynik (upraszczając) oznacza, że całkowity czas wykonania programu wynosił 13.073s (real), z czego scheduler CPU przypisał kontekst wykonania programu do CPU na łacznie 12.960s (user). Pozostały doliczony czas 0.110s (sys), to czas na inne niezbędne procedury systemu operacyjnego w kontekście procesora.
Podczas wykonania programu, jeden z dwóch rdzeni procesora ARM, był w całości zajęty przez algorytm:
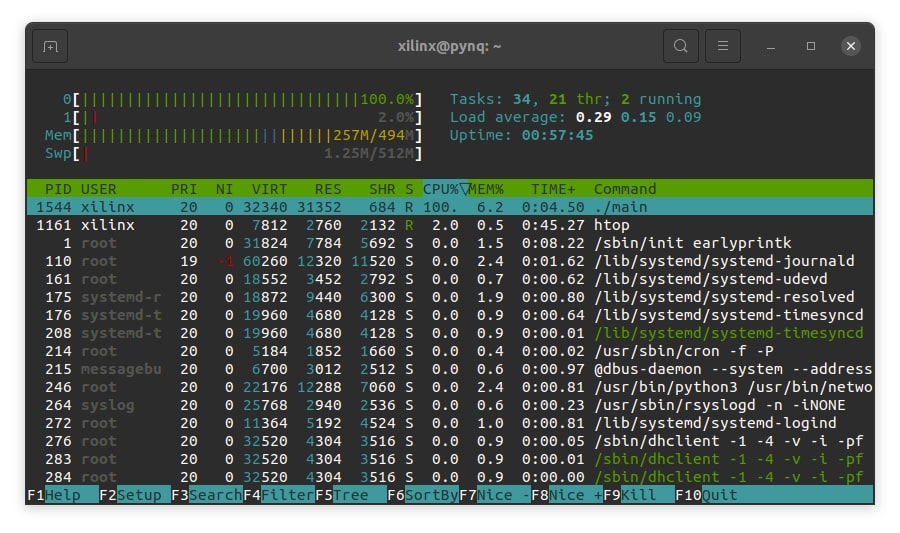
Myśląc logicznie, maksymalnie dwie instancje algorytmu mogą pracować w tym samym czasie z podobnym czasem wykonania:
W tym momencie obydwa rdzenie ARM zostają zajęte przez algorytm:
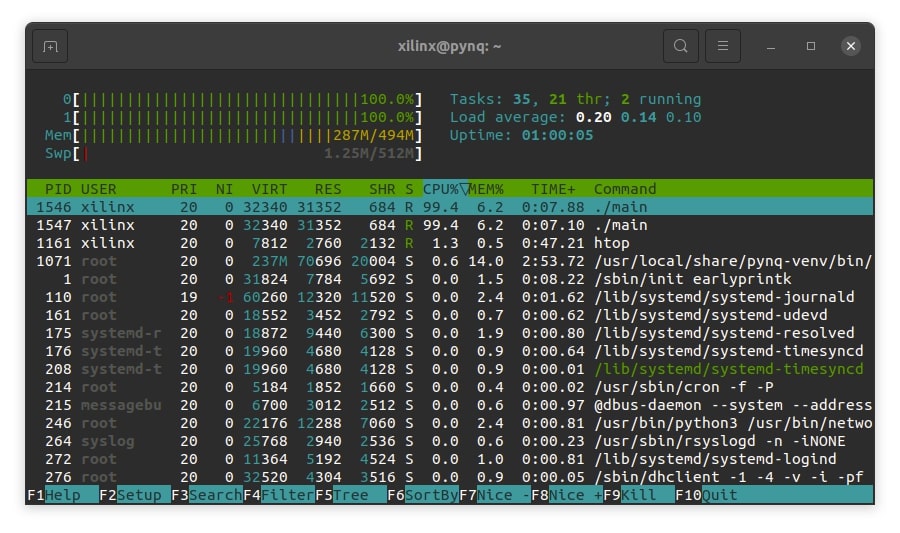
Przy uruchomieniu większej liczby instancji równolegle:
Czasy wykonania poszczególnych instancji aplikacji (real) są większe, natomiast czas (user + sys) wygląda na podobny. Tak jak poprzednio, scheduler CPU przepiął kontekst wykonania procesu do CPU na 12.097 + 0.090 sekund – tyle czasu mocy obliczeniowej procesora wymagane jest do wygenerowania hasha z 31457280 bajtów (30 MB) danych przez implementację algorytmu w C. Ogólne czasy wykonania (real) programów były wyższe, w przypadku trzech instancji, ponieważ na płytce PYNQ-Z1, procesor ARM posiada tylko dwa rdzenie.
Procesor ARM pracuje z maksymalną częstotliwością 650 MHz, pamięć DDR – 525 MHz.
Uruchomienie rdzenia algorytmu FPGA w środowiska Python
Pojemność układu FPGA użytego w ZYNQ-7000, pozwoliła na implementację dwóch rdzeni algorytmu, które mogą przetwarzać dane współbieżnie. Do testu przygotowano dwa ciągłe obszary pamięci, o rozmiarze 31457280 bajtów (30 MB), jeden wypełniony zerami, drugi jedynkami.
Dla pojedynczego bloku wypełnionego zerami:
Dla dwóch bloków danych przetwarzanych współbieżnie przez dwa rdzenie algorytmu, pierwszy wypełniony zerami, drugi jedynkami:
Użycie CPU w tym teście było znikome:
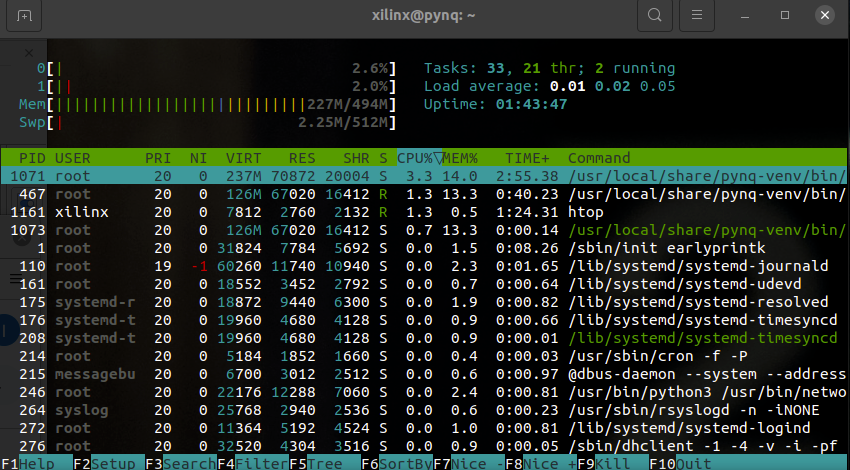
Warto zauważyć, że rdzenie algorytmu pracują asynchronicznie względem głównego kodu w języku Python. Oznacza to, że podczas oczekiwania na wynik, poprzez sprawdzanie stanu flagi AP_DONE, można wykonywać inne zadania na CPU ARM, co daje jeszcze więcej możliwości.
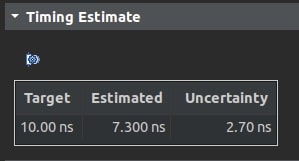
Zegar źródłowy układu FPGA, do którego przyłączone są rdzenie algorytmu, został skonfigurowany zgodnie z docelowym cyklem syntezy RTL algorytmu, czyli 100 MHz (10 ns).
Skoro linia zegara jest konfigurowalna, to czy można ustawić wyższą częstotliwość pracy? Oczywiście, że tak, lecz w skrajnych przypadkach algorytm traci wiarygodność przetwarzania.
Przy podkręceniu zegara źródłowego z 100 MHz do 200 MHz, wyniki (dla testowanych bloków danych) nadal są sensowne:
Przy wyższych częstotliwościach, algorytm traci wiarygodność, lub blok wykonania się nie kończy. Najpewniej mają już znaczenie odległości połączeń między blokami funkcjonalnymi w układzie FPGA, które zostały przewidziane (wygenerowane przez proces routingu w Xilinx Vivado) dla częstotliwości 100 MHz.
W przypadku powyższej implementacji algorytmu w układzie FPGA nie mamy do dyspozycji schedulera, nie jest możliwe uruchomienie więcej współbieżnych (lub współbieżnie-przełączanych) instancji niż liczba rdzeni algorytmu.
Porównanie wyników
Czas wykonania pojedynczej instancji algorytmu C na CPU ARM: ~ 13.037s.
Czas wykonania dwóch równoległych instancji CPU ARM: ~ 13.152s.
Czas wykonania trzech równoległych instancji CPU ARM: ~ 19.442s.
Czas wykonania pojedynczego rdzenia algorytmu na układzie FPGA: ~ 2.363s.
Czas wykonania dwóch rdzeni pracujących równolegle na układzie FPGA: ~ 2.546s.
Czas wykonania po (niezalecanym) podkręceniu linii zegara układu FPGA: ~ 1.726s.
Algorytm w testach był traktowany jako “czarna skrzynka”, wiedząc jednak, że jest to funkcja haszująca SHA-1, nie powinno również zabraknąć pomiaru wykonania na CPU ARM, ze wsparciem dedykowanych bibliotek wykorzystujących specjalne instrukcje procesora przeznaczone do takich obliczeń:
Wnioski
Algorytm numeryczny, który został przekształcony do postaci układu elektronicznego i uruchomiony na układzie FPGA, przetwarza dane znacząco szybciej, nie obciążając procesora. Otwiera to drogę dla rozszerzonej współbieżności – rdzenie algorytmu są współbieżne względem siebie, a wykonanie kodu na układzie FPGA względem głównego procesora.
Dzięki frameworkowi PYNQ interakcja z układem FPGA ze środowiska Python nie różni się zbyt wiele od wywołania np. metody klasy, dzięki czemu przeniesienie obliczeń z istniejącego kodu do układu (pośrednio poprzez kod C/C++) nie jest skomplikowane.
Powyższe zastosowanie FPGA to wierzchołek góry lodowej. Wspomniana płytka prototypowa PYNQ-Z1 posiada np. wejście oraz wyjście HDMI, które jest połączone z układem FPGA. Co za tym idzie, można w sposób surowy generować obraz wideo, lub przetwarzać w czasie rzeczywistym HDMI IN -> HDMI OUT, a wszystko to może być sterowane z języka Python!
Wszystkie zdjęcia użyte w publikacji pochodzą z archiwum Autora.
Podobne artykuły
Jak napisać własny emulator Chip-8?

Kiedyś na jednego inżyniera embedded przypadała jedna oferta pracy. Historia Michała Zająca

Czy Alexa może być wszędzie? Jak zintegrować Alexę z urządzeniami domowymi
