Legacy code i szybsze testy automatyczne
Gdy projekt jest bardzo duży, kod ciężko testowalny, a większość testów to testy funkcjonalne – mierzymy się z problemem: kończymy zadanie, user story bądź cały sprint i czekamy na testy godzinami. Można to przyspieszyć, nawet w aplikacji pamiętającej czasy dinozaurów chodzących po ziemi.

Damian Kęska. Programista PHP w FINGO. Najnowszymi technologiami interesuje się od najmłodszych lat. Już pod koniec szkoły podstawowej pisał pierwsze skrypty w Bashu, w liceum zaczął tworzyć strony www z użyciem PHP. Na co dzień pracuje z technologiami webowymi opartymi o PHP oraz Angular. Entuzjasta wolnego oprogramowania oraz Linuksa. Po godzinach, w wolnym czasie, programuje także w Pythonie.
Przede wszystkim warto wprowadzić do nowego kodu testy jednostkowe – wydzielić zależności na zewnątrz naszego kodu i testować to, co naprawdę tworzymy. Testy mają sprawdzać nasz kod logiczny, nie biblioteki czy ORM. Wprowadzenie testów jednostkowych to jednak krok długofalowy, niedający natychmiastowych efektów – dlatego pokażę, co można zrobić oprócz tego.
Na wstępie powiem, że można by było o tym napisać książkę, natomiast artykuł ten będzie przedstawiał temat w bardzo wielkim skrócie, w zasadzie poruszę w nim praktyczną koncepcję na bazie własnego doświadczenia – zakładając trudniejszy scenariusz, kiedy projekt ma sporo testów używających bazy danych.
Spis treści
Konfiguracja PHP
Czy przy każdym uruchomieniu testów potrzebujemy rozszerzenia xdebug? Pomaga ono zmierzyć pokrycie kodu, ale wyniki wykonania testów nie zależą od niego, a jego obecność wydłuża wykonywanie kodu PHP.
Więc jeśli chcemy zobaczyć, czy nasza modyfikacja lub nowa funkcjonalność nie wywołała regresji w starszym kodzie, możemy uruchomić testy z wyłączonym xdebug. Gdy potrzebujemy zmierzyć, ile kodu zostało pokrytego, możemy go włączyć, na przykład poprzez przełącznik z linii poleceń w samym PHP.
Drugą przydatną rzeczą w samym interpreterze jest moduł opcache, który służy do przechowywania w pamięci RAM skompilowanego bajtokodu plików PHP. Odpowiednia konfiguracja może znacząco przyspieszyć wczytywanie plików aplikacji oraz plików z testami, poprzez zredukowanie całkowitego czasu o czas potrzebnego na ponowną kompilację kodu źródłowego.
Warto przy używaniu opcache pamiętać o konfiguracji dla środowiska deweloperskiego, która pozwoli odpowiednio walidować pliki (np. po znacznikach czasowych w systemie plików), czy zachowywać komentarze (przykładowo: ważne jest to dla PhpUnit, gdyż używa on adnotacji).
Przykładowa konfiguracja opcache dla środowiska deweloperskiego:
opcache.max_accelerated_files=80000 # zależy od wielkości projektu opcache.max_wasted_percentage=5 opcache.memory_consumption=256 # zależy od wielkości projektu opcache.enable=1 opcache.enable_cli=1 opcache.validate_timestamps=1 # sprawdzanie daty modyfikacji plików opcache.revalidate_freq=0 # sprawdzanie daty ZAWSZE opcache.save_comments=1 # PhpUnit używa adnotacji opcache.load_comments=1
Wartość dla max_accelerated_files możemy zmierzyć przy pomocy polecenia find ./ -name ‘*.php’|wc -l.
Wielowątkowe testy z użyciem bazy danych
Pomimo licznych optymalizacji nasze testy przeglądarkowe wciąż wykonują się 8 godzin, a funkcjonalne z jednostkowymi 2 godziny. Została już tylko jedna opcja – rozdzielić je na mniej więcej równe grupy i uruchomić równolegle. I tu zaczyna się robić ciekawie.
1. Architektura
Na początku zacznę od architektury. Dobrze jest uzbroić się w kontenery (w końcu ciężko jest przy dużym projekcie wciąż grzebać łopatką w piasku), dostawa na serwery produkcyjne upraszcza się z odrobiną automatyzacji.
Popularny ostatnio docker powinien przyjść nam z pomocą. Warto aplikację, czyli php-fpm + ewentualnie webserver wstawić do jednego kontanera lub do dwóch osobnych, bazę danych do osobnego kontenera i to samo zrobić dla selenium z vnc (oraz ewentualnie cache, jeśli używamy). Na zachętę dodam, że 12-letni kod z nazwami zmiennych po niemiecku i logice w szablonach też się w dockerze znakomicie uruchamia, więc żaden projekt nie jest na to za stary.
Przykładowa struktura środowiska:
- application,
- db,
- selenium_chrome_vnc,
- cache.
Wstawienie aplikacji do kontenerów – przede wszystkim w kontekście testów – daje nam łatwą możliwość skalowania bazy danych, selenium oraz ewentualnie serwera cache (możemy w nim zamiast skalowania na przykład prefiksować klucze, jeśli nie chcemy skalować kontenera).
Przy pomocy zmiennych środowiskowych, lub ze skryptami generującymi pliki konfiguracyjne, możemy przekazać nazwę instancji bazy danych do aplikacji i testować manualnie nasz kod na dwóch bazach danych oraz uruchamiać równolegle testy automatyczne.
Z założenia wiemy, że nasza aplikacja potrzebuje do działania wielu kontenerów, warto więc użyć docker-compose, który pozwala zarządzać całym środowiskiem przy pomocy plików konfiguracyjnych.
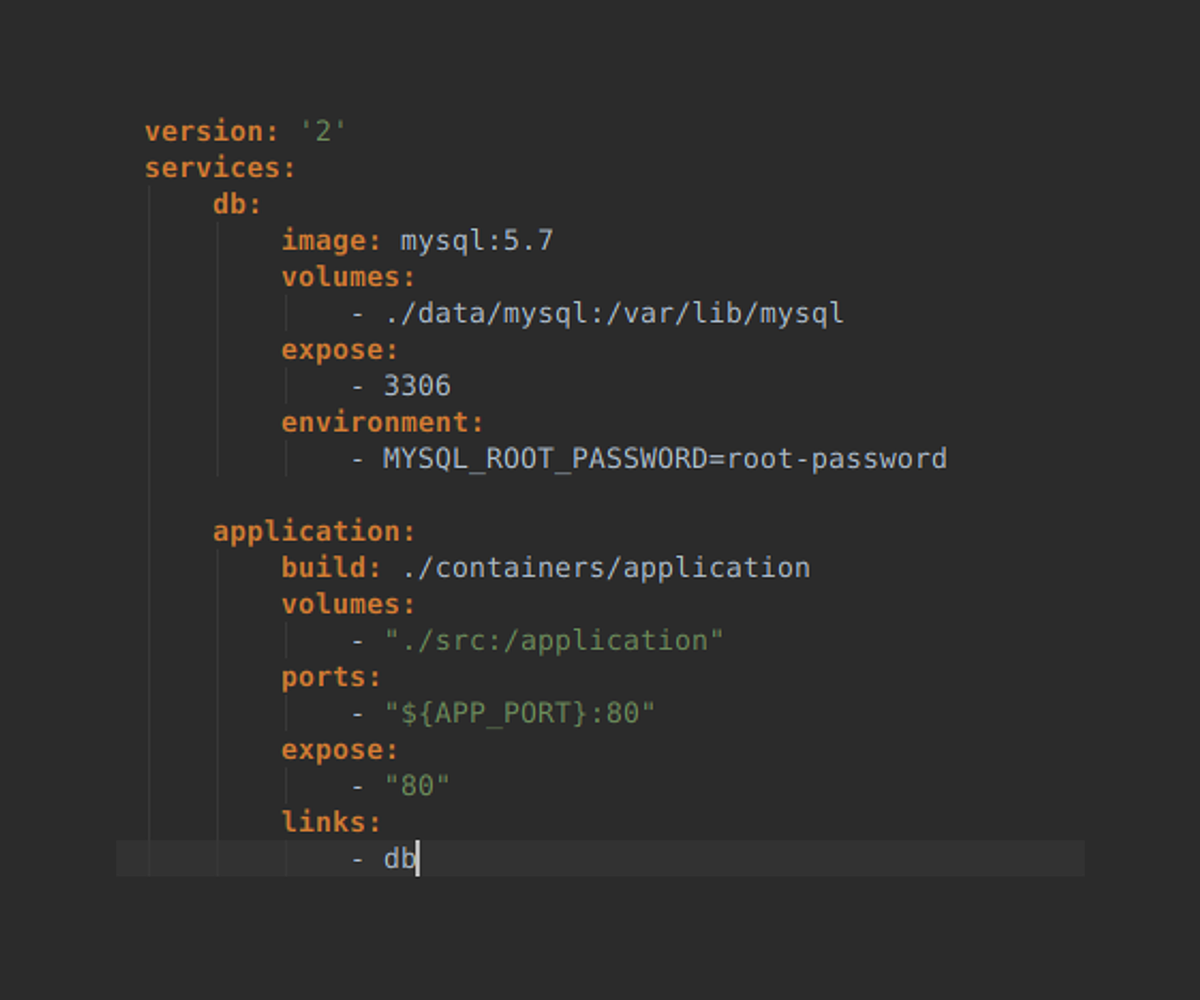
Przykładowy plik docker-compose.yml, zawierający definicję dwóch kontenerów:

Compose daje możliwość łączenia wielu kontenerów ze sobą, a także używania wielu plików konfiguracyjnych, które mogą się łączyć w jeden. Dobrym przykładem może być bazowy plik konfiguracyjny docker-compose.yml – używany na produkcji, docker-compose.dev.yml – dodający funkcje deweloperskie oraz docker-compose.osx.yml – zawierający poprawki umożliwiające uruchomienie środowiska deweloperskiego na systemie OS X.
Oprócz tego mamy jeszcze możliwość definiowania zmiennych środowiskowych w pliku .env, który dodajemy do .gitignore i tworzymy mu szablon (np. .env-template), następnie generujemy swój plik konfiguracyjny. W powyższym przykładzie możemy zmienić sobie port aplikacji, dzięki czemu uruchomimy dwie aplikacje w dwóch środowiskach na różnych portach.
Jeśli przeraża Cię ilość nowych poleceń do zapamiętania, gorąco polecam użycie starego jak świat uniksowego standardu – Makefile. Pozwala on na zdefiniowanie, w sposób zrozumiały dla każdego dewelopera, zestawu komend do zbudowania projektu i wydawania pojedynczych lub połączonych ze sobą poleceń w stylu make pull build start:dev.
Pomocne wskazówki:
1. Ustaw nazwę środowiska przy pomocy przełącznika „-p” (docker-compose), ułatwi to później znajdowanie kontenerów i debugowanie – w przeciwnym razie będzie nią nazwa katalogu…
2. Nie twórz tony zależnych od siebie wzajemnie skryptów w bashu, z czasem zrobi się bałagan.
3. Pozostaw Makefile wolny od instrukcji warunkowych, wykonaj te niezbędne nad wszystkimi zadaniami i wygeneruj z nich zmienne (mnie udało się zostawić tylko i wyłącznie jedną instrukcję, sprawdzającą czy system operacyjny to OS X).
4. Kontenery skalowalne, np. baza danych, cache, selenium, nie mogą mieć forwardowania portów, bo te będą się na siebie nakładać.
5. Na OS X może być niezbędne użycie docker-sync dla uzyskania rozsądnej wydajności.
6. Konfiguracja OS X ze względu na użycie wirtualnej maszyny może komplikować dostęp do VNC/selenium, wtedy można postawić dodatkowy kontener z nginx (tcp forwarding), który potrafi wystawić na zewnątrz skalowalne kontenery. W ostateczności można skorzystać z sieci lokalnej (co nie jest zalecane).
7. Warto dodać możliwość ustawienia portów aplikacji oraz możliwość włączenia/wyłączenia opcache czy xdebug z poziomu pliku .env, tak aby każdy deweloper miał możliwość łatwej konfiguracji.
8. Jeśli Twoja aplikacja wymaga stworzenia plików konfiguracyjnych o większej strukturze, możesz użyć standardu jinja2, który wygląda jak szablon Twig i w ten sposób z np. poziomu Pythona możesz generować pliki konfiguracyjne, mając do dyspozycji zmienne środowiskowe jako zmienne wewnątrz szablonu.
9. Twórz dokumentacje w README.md, będą widoczne w gitlabie/githubie/bitbuckecie; w Makefile dodawaj komentarze do zadań.
10. Skorzystaj z generatora polecenia „help” dla Makefile (przykład: https://github.com/Elao/symfony-standard/blob/master/Makefile#L10), dzięki któremu zespół będzie znać listę poleceń. W opisie poleceń umieść obsługiwane zmienne np. dla polecenia make scale może to być parametr INSTANCES_COUNT=5.
2. Schemat działania
Skoro mamy już architekturę, to jesteśmy w stanie restartować kontenery, wysyłać do nich polecenia przy pomocy docker exec lub docker-compose exec, a także możemy je skalować, używając na przykład docker-compose up –scale db=5.
Właściwie to, w jaki sposób będziemy odtwarzać bazę danych dla testów funkcjonalnych, zależy od nas, ja przedstawię jedynie wybraną przez mnie metodę.
Docker przede wszystkim daje możliwość utworzenia obrazu i skopiowania go wielokrotnie. Pozwala także na łatwe zamontowanie katalogu do pamięci RAM, co znacznie zwiększa wydajność, na przykład w przypadku bazy danych.
Skorzystajmy z tych dwóch właściwości i zbudujmy obraz, który będzie:
1. Zawierać kopię naszej bazy danych.
2. Zawierać skrypt, który wyłączy bazę danych, następnie przywróci backup i uruchomi bazę danych ponownie (u mnie trwa to może 0.3 sekundy).
3. Będzie mieć zamontowaną bazę danych do pamięci RAM, aby uzyskać większą prędkość odczytu i zapisu danych (nazywa się to tmpfs).
Zakładając, że skrypt nazywa się /rollback-database-from-backup.sh, aby z niego skorzystać, można wydać proste polecenie: sudo docker exec -i nazwa_srodowiska_db_5 /rollback-database-from-backup.sh – uruchomi ono skrypt dla instancji bazy danych numer 5.
Zakładając, że skrypt nazywa się /rollback-database-from-backup.sh, aby z niego skorzystać, można wydać proste polecenie: sudo docker exec -i nazwa_srodowiska_db_5 /rollback-database-from-backup.sh – uruchomi ono skrypt dla instancji bazy danych numer 5.
Skrypt powinien poczekać aż baza danych zostanie uruchomiona, następnie zasygnalizować, że procedura przebiegła pomyślnie, wypisując informację do stdout.
Aby mieć możliwość wykonywania takiego polecenia z poziomu testów, możemy pokusić się o stworzenie bardzo małego serwisu API, dosłownie „nano serwisu”, który sprawdzi poprawność wejściowych danych i wykona nasz skrypt wewnątrz uruchomionego kontenera. Polecam język Python oraz Tornado Framework – można w nim zmieścić całość w 120 liniach kodu wraz z inicjalizacją frameworka. Python jest bardzo podobny do PHP, co pozwala na łatwiejsze zrozumienie kodu przez resztę deweloperów w zespole.
3. Uruchamianie testów i zbieranie wyników
Na etapie, na którym aplikacja jest gotowa do równoległego działania w jednym środowisku, możemy przystąpić do uruchamiania wielu testów jednocześnie.
Cała „magia” i prostota rozwiązania polega na tym, że gdy testy potrzebują bazy danych, wywołują proste zapytanie do serwisu API, następnie skrypt wewnątrz kontenera robi swoje i zwraca gotowość wybranej instancji – dzięki temu nie potrzebna jest żadna nakładka uruchamiająca testy, wystarczy zwykły, prosty ./vendor/bin/phpunit z informacją o numerze instancji. Metody setUp() i tearDown() w PhpUnit powinny zająć się wszystkim.
Poniżej przykładowy skrypt w bashu, prototyp. Początki nie muszą być większymi, docelowymi rozwiązaniami.
#!/bin/bash
echo "" > ./tests.log
max_workers=2
prefix="db_"
run_test () {
sudo docker-compose exec application /bin/bash -c "./vendor/bin/phpunit -c $(pwd)/test/phpunit.xml.dist $@"
}
wait_until_free_pipeline () {
while [[ $(ps aux | grep "phpunit" | grep -v "grep" | wc -l) -gt $1 ]]; do
sleep 0.1
done
}
find_free_db_instance () {
instances_max_num=$1
prefix=$2
for i in $(seq 1 $instances_max_num); do
if [[ $(ps aux | grep "phpunit" | grep -v "grep" | grep "DB_INSTANCE=${prefix}_${i}") == "" ]]; then
echo "DB_INSTANCE=${prefix}${i}"
return 0
fi
done
return 1
}
for file in $(find ./test -name '*Test.php'); do
i=$((i+1))
DB_INSTANCE=$(find_free_db_instance $max_workers $prefix)
echo " >> $file (${DB_INSTANCE})"
/bin/bash -c "DB_INSTANCE=${DB_INSTANCE} ./vendor/bin/phpunit -c $(pwd)/site/test/phpunit.xml.dist $file" >> ./tests.log &
wait_until_free_pipeline $max_workers
done
W przypadku gdy testy sypią błędami, wiele rzeczy może pójść nie tak – skrypt bazy danych może przedwcześnie informować o gotowości (w końcu liczą się milisekundy), testy same w sobie mogą posiadać zależności między sobą, bądź któraś z zależności zmieniających stan w postaci cache lub innego serwisu API nie zostanie opakowana w kontener i wyskalowana.
Aby poradzić sobie z testami, które mają niejawne zależności pomiędzy sobą, możemy je w PhpDoc oznaczać jakimś markerem – można taki marker łatwo wydobyć poprzez Reflection.
Innym sposobem jest zaimplementowanie interfejsu wymuszającego implementację metody odpowiedzialnej za informowanie o tym, które testy w jaki sposób przygotować. Jednak raczej nic nie pomoże, jeśli istnieją zależności pomiędzy testami w różnych plikach – takie testy należy poprawić.
Zakładając, że doprowadziliśmy wszystkie testy do porządku, uruchamiają się i przechodzą – dobrze jest mieć z wielowątkowego skryptu poprawny exit code oraz rozróżnienie, które testy wykonały się poprawnie, poprzez przepisanie skryptu w Bashu do Go, Pythona lub do dowolnego innego języka, który potrafi przetworzyć wyjście z testów, kontrolować kilka kolejek na raz i czuwać nad nimi.
To w zasadzie wszystko. Na koniec postaram się nieco podsumować powyższe rozwiązanie.

Niewątpliwe zalety
- Uzyskanie dużo szybszego wyniku testów, co jest szczególnie ważne przy podejmowaniu decyzji, czy ostatecznie można wypuścić nową wersję aplikacji.
- Użycie standardów – API pozwala na łatwy dostęp z poziomu testów PHP-owych, jak i z poziomu Shella (można stworzyć sobie alias w Bashu na import/rebuild bazy danych).
- Zarządzanie infrastrukturą poprzez pliki konfiguracyjne daje większą transparentność odnośnie infrastruktury, a przynajmniej jej części.
- Użycie Makefile daje porządek, dodatkową walidację do wykonywanych poleceń oraz możliwość łączenia kilku poleceń w łańcuchy np. “make pull build start”.
Wady
- Na dockera trzeba się przestawić. “Ryba nie pływa bez wody” – tak powtarzam, gdy ktoś próbuje uruchamiać konsolę Symfony poza działającym środowiskiem na swoim lokalnym Shellu, zamiast wewnątrz kontenera dockerowego.
- Większy projekt wymaga ogromnej ilości pamięci ram, nawet 8 GB.
- Więcej kodu infrastrukturalnego do utrzymania.
Testy automatyczne zapewniają większe poczucie bezpieczeństwa pracy zespołu. Często spotykanym punktem w tzw. “definition of done” jest napisanie testu oraz upewnienie się, że inne działają. Wprowadzenie testów w ogromnej i długo rozwijanej aplikacji – na początek np. prostych testów funkcjonalnych typu – “czy kontroler dla podanego requestu zwraca poprawnie przeliczoną wartość”, jest już minimalnym zabezpieczeniem, które jest w stanie zasygnalizować błąd.
Kiedy w projekcie przed zakończeniem sprintu uruchamiamy pipeline – warto mieć wynik testów przed godziną szesnastą.
Artykuł został pierwotnie opublikowany na blog.fingo.pl.
Podobne artykuły

Jak budować efektywną strategię QA i usprawnić współpracę na linii Dev-QA

Czy QA to nadal drzwi do IT i co rynek „gotuje” testerom? Wywiad z Jakubem Klechem

Pair testing: jak developerzy i testerzy wspólnie dbają o jakość

Jako twórcy aplikacji mało wiemy o odbiorcach. O użyteczności i dostępności w IT

Klienci chcą rozwiązań problemów, a nie fajerwerków. O zjawisku overengineeringu

Zmienił się apetyt na ryzyko. Organizacje w końcu kładą nacisk na budowę kultury jakości

Automatyzuj przewidywalną część pracy. Zaoszczędzony czas poświęć na dogłębną analizę kodu
