Dynamiczne generowanie typów w C#. Na przykładzie całkowitej abstrakcji Entity Framework (cz.1)
Entity Framework to prawdopodobnie najbardziej rozpowszechniony ORM w świecie .NET-u. Ma jednak swoje wady i jedną z nich postanowiliśmy wyeliminować w projekcie, w którym aktualnie biorę udział.

Kuba Pilecki. Freelancer, Senior Software Engineer & Architekt, z ponad 15-letnim doświadczeniem w projektowaniu i programowaniu aplikacji oraz systemów IT. Posiada portfolio ponad 20 zrealizowanych projektów. Fan C# ale równie sprawnie porusza się w wielu innych językach i technologiach. Posiada rozległą wiedzę na temat nowoczesnych technologii, narzędzi i metodologii. Wyznaje zasadę, że nie ma rzeczy niemożliwych
Zwykle mówi się, że ORM, poza oczywistymi rzeczami jak mapowanie rekordów na obiekty, zapewnia także możliwość łatwej migracji z jednego systemu bazodanowego na inny. Prawdę mówiąc, w całym swoim życiu pamiętam jeden projekt (a było ich wiele), w którym coś takiego miało miejsce. Ktoś pewnego dnia przyszedł i stwierdził „hej, zmieniamy DBMS X na Y”.
W dobie baz typu NoSQL, a także ciągle raczkującego .NET Core, bardziej prawdopodobna jest zmiana jednego ORM-a na drugi. Czy to z powodu zmiany decyzji o trzymaniu pewnego zbioru danych w bazie NoSQL zamiast tradycyjnej, czy to z powodu tego, że np. EF Core czegoś tam jeszcze nie oferuje i trzeba poszukać alternatywy. Albo że ta alternatywa jest zbyt ciężka i w sumie to lepiej napisać warstwę dostępu po swojemu.
Ugruntowały się już różne patenty na tego typu zdarzenia. Mamy więc repozytoria, które robią nam za warstwę abstrakcji pomiędzy logiką biznesową, a fizycznym zapisywaniem naszych danych „gdzieś w tajemniczym miejscu”. Mamy koncepcje lekkich POCO, służących do mapowania danych z płaskiego świata krotek na rozbudowane klasy. Itp. Itd.
Wszystko fajnie, ale w naszym projekcie chcemy więcej. Chcemy mieć możliwość cichej podmiany ORM-a, w taki sposób, żeby wszystkie aplikacje działały jak dotychczas i nawet nie zauważyły różnicy. Żeby w samym kodzie mikrousług nie trzeba było zmieniać ani jednej linijki kodu, żeby cała zmiana polegała na podmianie jednej biblioteki na drugą. Żeby faktycznie fizyczne zapisywanie danych odbywało się „gdzieś w tajemniczym miejscu”, o którym developerzy usług aplikacji nie myślą prawie.
I to właśnie pewnego wieczoru ostatnimi czasu udało mi się osiągnąć, a teraz z chęcią się tym z wami podzielę. Ale sama zabawa z EF jest tutaj tylko pretekstem do poznania i opanowania jednej z najpotężniejszych magicznych sztuczek w arsenale .NET-owca. Także nawet jeżeli uważasz nasze motywacje za bzdurne albo sądzisz, że nigdy tego typu operacji nie będziesz przeprowadzać, to i tak zachęcam do lektury.

Spis treści
Cel
Celem naszego dzisiejszego małego projektu jest ukrycie Entity Framework-a za warstwą całkowitej abstrakcji, która zapewni możliwie pełne odizolowanie aplikacji, od wszelkich koncepcji EF. Oczywiście przy zachowaniu 100% funkcjonalności (no ok, raczej będzie to jakieś 95%, ale nie można mieć wszystkiego). Zbierzmy jakąś minimalną specyfikację:
Nasz główny cel można określić następująco:
- Żaden podprojekt solucji nie posiada referencji do Entity Framework-a, z wyjątkiem projektu oferującego warstwę abstrakcji nad EF;
Z tego wynikają szczegółowe ograniczenia i cele, podane poniżej:
- Brak definicji właściwości typu DbSet<T> w zbiorczej klasie dziedziczącej po DbContext;
- Brak klasy dziedziczącej z DbContext w ogóle;
- Nadal jednak chcemy mieć jakąś klasę kontekstową, której obiekty możemy użyć do wyznaczania granic kontekstu operacji na bazie danych;
- Używamy uniwersalnych atrybutów (System.ComponentModel.DataAnnotations) na klasach i właściwościach encji, w celu wymuszenia odpowiedniego kształtu tabel w bazie danych;
Mała dygresja
Warto nadmienić, że „stary” .NET Framework sam wymusi te ograniczenia, ponieważ w jego przypadku zależności są nieprzechodnie. Weźmy solucję z dwoma projektami Projekt_A i Projekt_B. Załóżmy, że w Projekcie_A mamy sobie referencję do Entity Framework-a i klasę MyContext dziedziczącą po DbContext. Nie użyjemy jej jednak w Projekcie_B, pomimo posiadania zależności do Projektu_A, dopóki do tego projektu nie dodamy również referencji do samego EF.
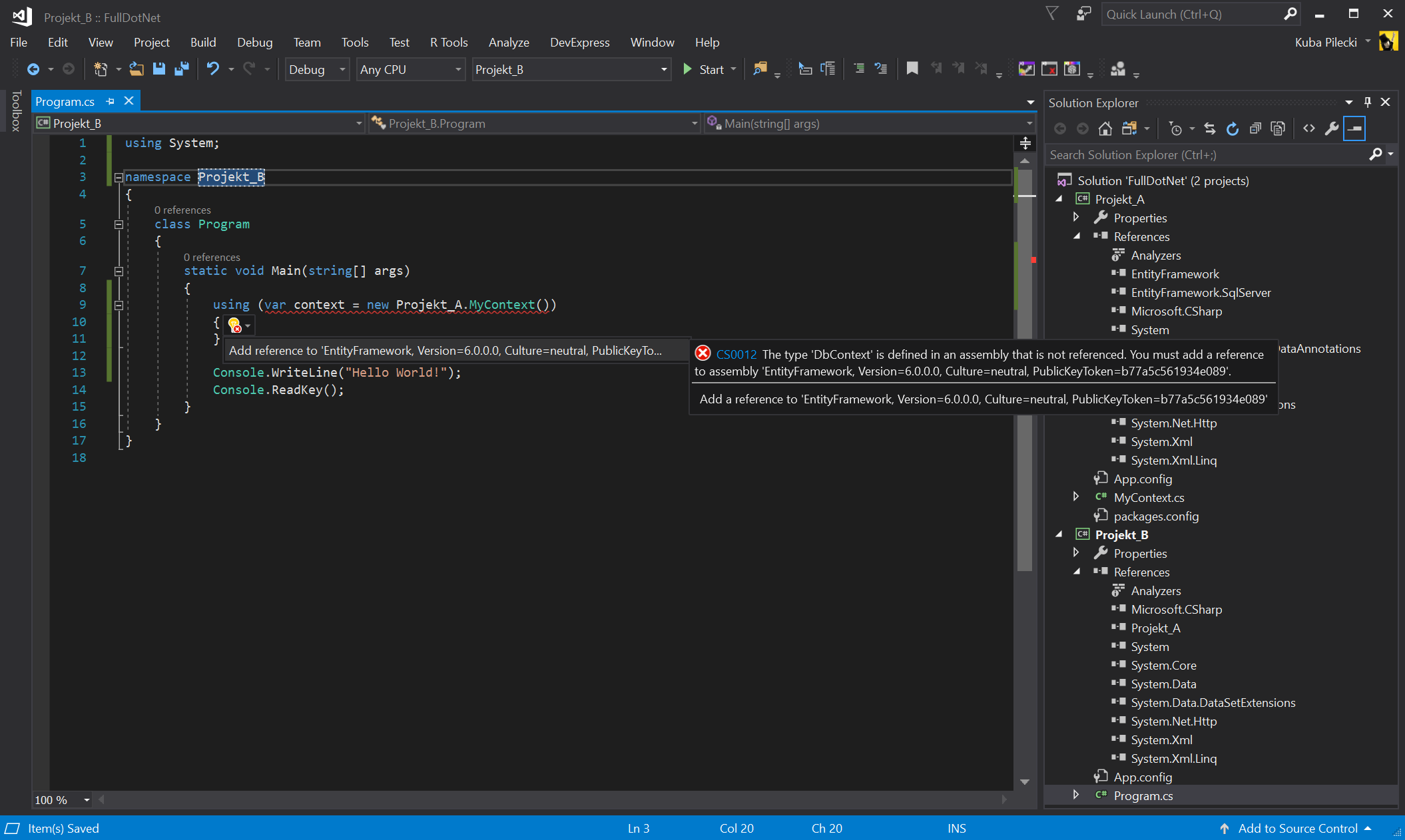
Rysunek 1 – Brak zależności do EF w Projekcie_B skutkuje błędem kompilacji, mimo że to Projekt_A jest odpowiedzialny za wszystko co związane z EF [.NET Framework 4.7.1]
.NET Core zachowuje się w tym wypadku inaczej, referencje są przechodnie i tworzą łańcuch. Wystarczy więc, że Projekt_A posiada zależność do EF, a wszystkie jego klasy i mechanizmy są domyślnie dostępne w Projekcie_B.
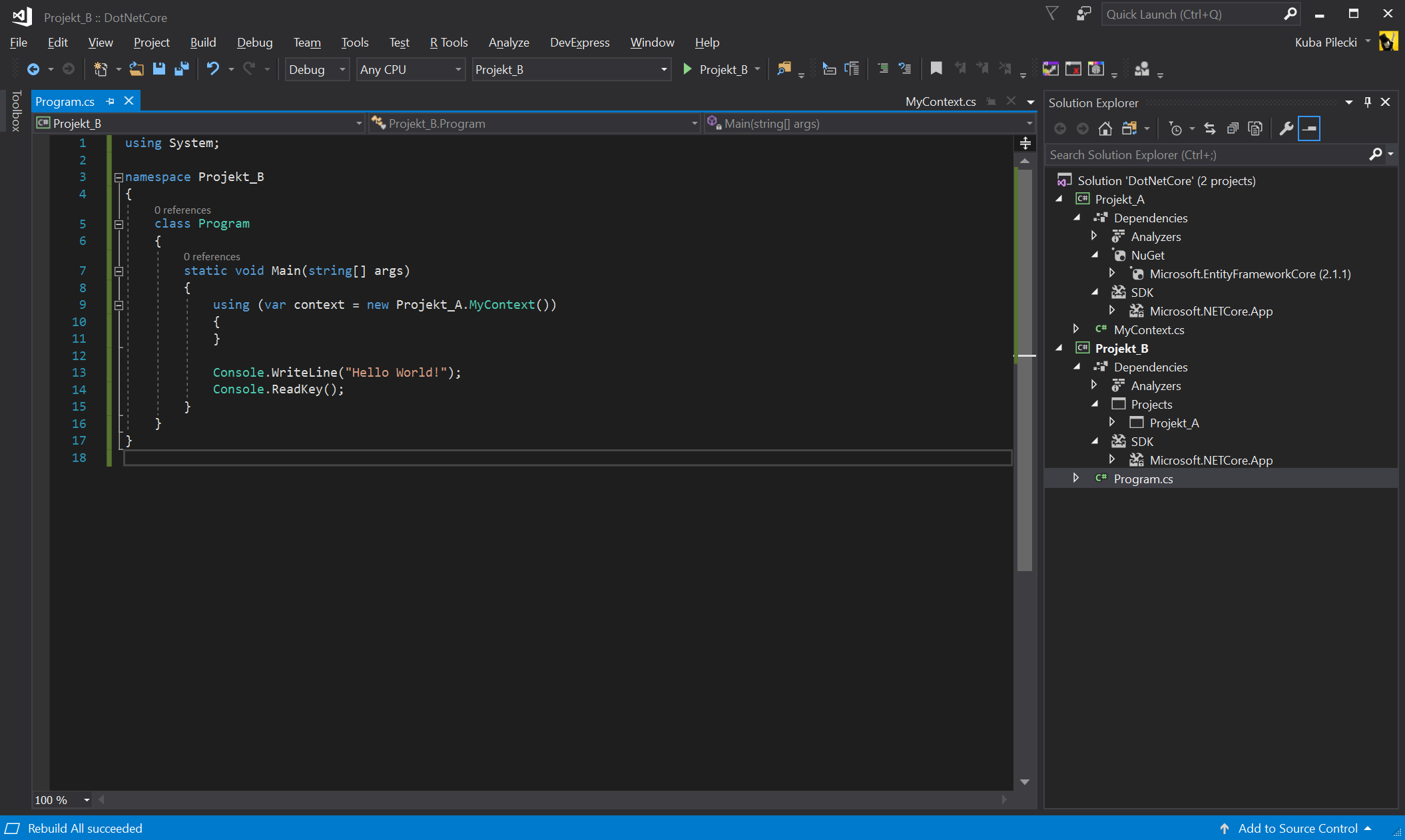
Rysunek 2 – W przypadku .NET Core zależności są domyślnie przechodnie, więc wystarcza nam referencja EF w Projekcie_A, a Projekt_B otrzymuje ją z automatu, po prostu posiadając Projekt_A w swoich zależnościach
Można tym zachowaniem również sterować, poprzez ustawienie odpowiednich flag w konfiguracji zależności (dokumentacja dostępna tutaj).
Prototyp
Papierowa mini specyfikacja zrobiona, zacznijmy prototypować nasze rozwiązanie. Ogólnie chcemy, aby możliwe utworzenie i używanie kontekstu dostępu do bazy danych w mniej-więcej następujący sposób:
var databaseContextFactory = new SqlDataSourceFactory(
"localhost", 5432, "username", "password", "database",
new Type[]
{
typeof(MyEntity),
typeof(MyOtherEntity)
}
);
Czyli bardzo podobnie do zwykłego EF, wołamy metodę GetContext() na fabryce kontekstów, otrzymujemy z tego obiekt reprezentujący kontekst operacji na bazie danych. Wewnątrz bloku prosimy o zwrócenie obiektu encji typu MyEntity, o identyfikatorze 123 i już. Oczywiście w pełnej aplikacji byśmy raczej posługiwali się osobnymi repozytoriami, pewnie także wstrzykiwaniem zależności itd., powyższy przykład jest jednak uproszczony, aby zachować czytelność.
Ok, skąd jednak nasza fabryczka kontekstów ma wiedzieć jakie są klasy reprezentujące encje, jak zainicjować bazę danych, tabele i relacje w niej? Załóżmy, znowu w uproszczonej wersji, że na początku naszego programu podamy klasy naszych encji do konstruktora fabryki, w ten sposób:
var databaseContextFactory = new SqlDataSourceFactory(
"localhost", 5432, "username", "password", "database",
new Type[]
{
typeof(MyEntity),
typeof(MyOtherEntity)
}
);
Czyli do konstruktora fabryki podajemy, poza oczywiście adresem hosta bazy danych, loginem i hasłem do niej, listę typów klas i mówimy „hej, to są encje, które mam w tym programie, zmapuj to sobie, zainicjalizuj co trzeba, nie wnikam jak i co, ma po prostu działać za moment”.
I znowu: w pełnym projekcie mielibyśmy tutaj prawdopodobnie jakieś automatyczne wykrywanie tych klas albo bardziej składny sposób ich rejestrowania, byłoby to jednak już rozszerzenie przedstawionej powyżej minimalnej koncepcji.
Implementacja naszej fabryki kontekstów mogłaby więc na początek wyglądać następująco:
using System;
namespace EFAbstraction
{
public class SqlDataSourceFactory
{
public SqlDataSourceFactory(string host, int port, string login, string password, string database, params Type[] entityTypes)
{
// TODO: Initialize
}
public ISqlDataSource CreateContext()
{
// TODO: Some magic
return null;
}
}
}
Dodajmy sobie jeszcze interfejs ISqlDataSource, który reprezentuje nasz faktyczny kontekst dostępu do bazy danych. Na teraz prosta rzecz, trzy podstawowe metody do dodawania, usuwania i pobierania encji:
using System;
namespace EFAbstraction
{
public interface ISqlDataSource : IDisposable
{
void Add<T>(T entity) where T : class;
void Delete<T>(T entity) where T : class;
T GetById<T>(int id) where T : class;
void SaveChanges();
}
}
No, to wiemy co chcemy osiągnąć, pytanie jak to zrobić?
Pomysły, prototypy, porażki
Czas na burzę mózgów. Wiadomo, że w jakiś sposób musimy opakować DbContext w klasę eksponującą nasz interfejs ISqlDataSource. To jest dość prosta sprawa, nie możemy co prawda zrobić po prostu klasy dziedziczącej po DbContext oraz implementującej ISqlDataSource, ponieważ solucja nam się wysypie, w przypadku „starego” .NET-a, z powodu braku referencji do Entity Framework-a. Zresztą byłoby to mało eleganckie. Zróbmy sobie więc prościutki adapter:
using System.Data.Entity;
namespace EFAbstraction
{
public class EFDataSource : ISqlDataSource
{
protected DbContext dbContext;
public EFDataSource(DbContext dbContext)
{
this.dbContext = dbContext;
}
public void Add<T>(T entity) where T : class
{
dbContext.Set<T>().Add(entity);
}
public void Delete<T>(T entity) where T : class
{
dbContext.Set<T>().Remove(entity);
}
public T GetById<T>(int id) where T : class
{
return dbContext.Set<T>().Find(id);
}
public void SaveChanges()
{
dbContext.SaveChanges();
}
public void Dispose()
{
if (dbContext != null)
{
dbContext.Dispose();
dbContext = null;
}
}
}
}
Ponownie, prosta rzecz, nasz adapter przyjmuje w konstruktorze prawdziwy DbContext i deleguje wszystkie operacje naszego interfejsu do niego. „Stary” .NET nie ma z tym problemów, ponieważ w żadnym miejscu projektu głównego nie używamy bezpośrednio czegokolwiek dotykającego DLLek obecnych jedynie w projekcie podrzędnym.
Tylko skąd wziąć nasz DbContext do naszego adaptera? Normalnie zrobilibyśmy sobie klasę dziedziczącą z DbContext, a w niej właściwości typu DbSet<T> rejestrujące wszystkie nasze encje, jednak to jest coś czego chcemy uniknąć. Lista encji będzie podawana dynamicznie w trakcie działania programu, a więc to rozwiązanie całkowicie odpada.
Pomysł #1 i porażka #1
Pierwsza myśl, jaka przyszła mi do głowy to wykorzystanie DbModelBuilder-a, poprzez przeładowanie metody OnModelCreating i rejestracja encji w ten sposób. Byłoby to coś tego typu:
protected override void OnModelCreating(DbModelBuilder modelBuilder)
{
foreach (var entityType in entityTypes)
{
modelBuilder.RegisterEntityType(entityType);
}
base.OnModelCreating(modelBuilder);
}
I w przypadku Entity Framework 6.x ten sposób może zadziałać. Niestety nie zadziała w przypadku Entity Framework Core, gdyż tam po prostu nie ma metody RegisterEntityType(Type). A pamiętajmy, że nasz projekt opiera się na .NET Core i takim też Entity Framework.
Pomysł #2 i porażka #2
Ok, więc pomysł numer dwa: również wykorzystajmy ModelBuilder i jego metodę Entity(Type), która zwraca EntityTypeBuilder. Niestety w takim wypadku musimy absolutnie wszystko zrobić ręcznie, określić wszystkie indeksy, klucze, relacje itd. Założyliśmy sobie, że rejestracja encji będzie czynnością prostą, a konfiguracja odbędzie się na podstawie atrybutów na właściwościach encji, użycie EntityTypeBuilder-a wymusiłoby w zasadzie napisanie własnego parsera tych atrybutów, lub przekopanie się przez kod źródłowy EFCore, dotarcie do tamtego parsera i użycie go. Próbowałem i było to jak szukanie igły w stogu siana. Zresztą nie puściłbym tego typu kodu na produkcję z uwagi na to, że użycie metod spoza publicznego API biblioteki równa się ryzyku wysypania się projektu przy aktualizacji biblioteki do nowszej wersji (inna sprawa, że w produkcji trzeba mieć naprawdę dobry powód, żeby aktualizację bibliotek w ogóle wykonać, ale mimo wszystko, po co sobie dokładać potencjalnych problemów).
Pomysł #3 i porażka #3
Pomysł numer trzy: typy dynamiczne i ExpandoObject! Czyli coś co przyszło lata temu, wraz z C# 4.0. Zróbmy sobie dynamicznie klasę, poustawiajmy jej właściwości w locie, wepchnijmy to na młynek Entity Framework-a, niech ten wykryje nasze dynamiczne DbSet-y i, korzystając z wbudowanych mechanizmów, zrobi całą inicjalizację bazy danych no i własną konfigurację.
Niestety, to też nie przejdzie. Entity Framework wyszukuje właściwości typu DbSet<T> na klasie przez zwykłą refleksję, a typy dynamiczne w C# opierają się na prostym słowniku Dictionary<string, object> i kilku sztuczkach kompilatora. Możecie to sprawdzić robiąc prosty test:
dynamic myFakeDbContext = new ExpandoObject();
myFakeDbContext.MyEntities = DbSet<MyEntity>();
object test = myFakeDbContext;
var props = test.GetType()
.GetProperties(BindingFlags.FlattenHierarchy
| BindingFlags.Instance | BindingFlags.Public | BindingFlags.NonPublic)
.Select(x => $"{x.Name} :: {x.PropertyType}").ToList();
Console.WriteLine(string.Join(Environment.NewLine, props));
Console.ReadKey();
Wynik będzie jednak niezachęcający:
Class :: System.Dynamic.ExpandoClass System.Collections.Generic.IDictionary<System.String,System.Object>.Keys :: System.Collections.Generic.ICollection`1[System.String] System.Collections.Generic.IDictionary<System.String,System.Object>.Values :: System.Collections.Generic.ICollection`1[System.Object] System.Collections.Generic.IDictionary<System.String,System.Object>.Item :: System.Object System.Collections.Generic.ICollection<System.Collections.Generic.KeyValuePair<System.String,System.Object>>.Count :: System.Int32 System.Collections.Generic.ICollection<System.Collections.Generic.KeyValuePair<System.String,System.Object>>.IsReadOnly :: System.Boolean
Nie ma tutaj naszej właściwości, to jest zwykły słownik i tyle. Mało tego, jak dodać tutaj atrybuty?
Nie da się? Wszystko się da
Stajemy więc przed wariacją na temat klasycznego problemu „mieć ciastko i zjeść ciastko”. Z jednej strony chcemy „mieć ciastko” czyli odizolować się od DbContext-u, z drugiej strony musimy „zjeść ciastko” czyli użyć DbContext-u. Paradoks? Trochę, ale jak wiadomo nie ma rzeczy niemożliwych. Potrzebujemy tylko odrobinę magii 🙂
Zróbmy sobie przerwę na krótkie pytanie: które z powyższych rozwiązań wydaje się najbardziej przystępne? Jedynka odpada – tej metody nie ma w EFCore i już. Dwójka… może być kusząca na pierwszy rzut oka, co to jest w końcu przeszukać właściwości klasy, wyciągnąć kilka atrybutów i zawołać odpowiednie metody na ich podstawie? Niestety szybko wyjdzie na jaw, że musimy oprogramować całkiem spory zakres tych atrybutów i rządzących nimi zasad. W efekcie przepisalibyśmy sporą część Entity Framework-a na nowo, zapewniając sobie również ból głowy w przyszłości, gdy EF będzie rósł, a wraz z nim będzie musiał rosnąć nasz parser.
Tak więc zostajemy z Trójeczką, która zresztą wydaje się najbardziej eleganckim rozwiązaniem – po prostu utwórzmy sobie dynamicznie nasz typ, wsadźmy mu odpowiednie właściwości, a resztą niech się zajmą już istniejące mechanizmy Entity Framework-a, czy jakiegokolwiek innego ORM-a, na który w przyszłości się ewentualnie przełączymy. Tylko jak to zrobić?

Magia
Najpierw na moment musimy cofnąć się do tego jak w ogóle działa .NET i jak to się dzieje, że możemy pisać programy w różnych językach i one wszystkie kończą jako biblioteki lub pliki wykonywalne .NET-u, które możemy potem dowolnie ze sobą wiązać.
Dzieje się tak, ponieważ kody źródłowe języków takich jak C# czy Visual Basic są kompilowane do kodu pośredniego, zwanego Common Intermediate Language (CIL, znany także jako MSIL), a dopiero ten kod jest w locie kompilowany do kodu maszynowego środowiska, w jakim nasza aplikacja jest uruchamiana (mniej-więcej w locie, tutaj wchodzą tematy takie jak JIT i AOT Compilation, którymi się teraz nie zajmiemy).
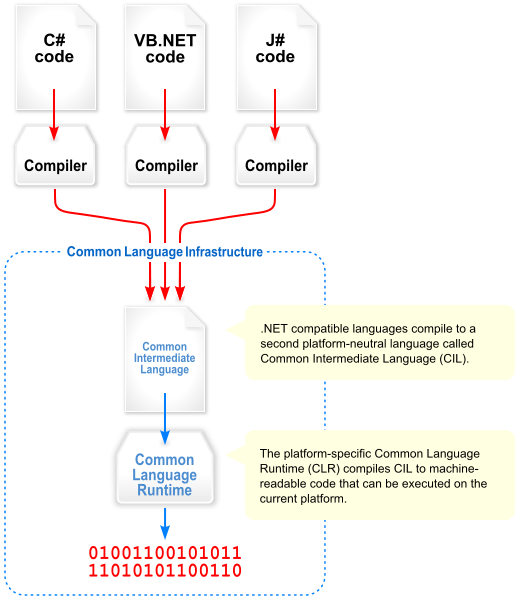
Rysunek 3 – Ogólny schemat kompilacji języków .NET do wspólnego języka CIL. Autor: Jarkko Piiroinen; Źródło: en.wikipedia.org. Na licencji Public Domain.
CIL jest więc czymś w rodzaju pośredniego asemblera w świecie .NET-u. I w sumie całkiem podobnie wygląda:
IL_0000 nop; IL_0001 ldarg.1 IL_0002 ldarg.2 IL_0003 add IL_0004 stloc.0 IL_0005 br.s IL_0007 ldloc.0 IL_0008 ret
Przedstawiony kod CIL, jak i wszystkie pozostałe w tym artykule, uzyskałem używając narzędzia o nazwie Msiler.
Powyższy listing przedstawia kod pośredni języka CIL, wygenerowany dla prostej metody zwracającej sumę dwóch argumentów, przedstawionej poniżej:
public int Add(int x, int y)
{
return x + y;
}
Jeżeli ktoś z was pisał lub chociaż czytał kiedyś kod kalkulatora, opartego o RPN (ang. Reverse Polish Notation), zauważy tu pewne podobieństwa – na stosie (ang. stack) kolejno poukładane są operandy (ldarg.1 odpowiadający zmiennej x oraz ldarg.2 odpowiadający zmiennej y), a po nim następuje operator, który je konsumuje (add) i następnie odkłada na stos wynik operacji (tutaj ldloc.0 – przypisanie do zmiennej lokalnej). Następnie ten wynik staje się operandem następnego operatora odnalezionego w dół stosu (w naszym wypadku jest to operator ret, czyli wyjście z metody). Jeżeli operacja musi sięgnąć po jakieś większe dane lub dane spoza swojego zakresu, wtedy znajdzie je na tzw. stercie (ang. heap).
Ok, ale czy to wszystko może nam jakoś pomóc rozwiązać nasz problem? Kod CIL powstaje przecież w wyniku kompilacji kodu C# przez kompilator, czy możemy go sobie ot tak wstrzyknąć w trakcie działania programu?
Odpowiedź brzmi: tak! Rozwiązaniem jest emisja kodu pośredniego do tymczasowej DLL-ki i dynamiczne załadowanie jej do domeny aktualnie uruchamianej aplikacji. Jest to technika powszechnie stosowana przez ASP.NET (Razor chociażby) czy właśnie Entity Framework. Gdy widzicie w okienku „Output” waszego Visual Studio przelatujące tajemnicze wpisy podobne do przedstawionego poniżej, to wiedzcie, że ładuje się dynamicznie utworzona biblioteka.
'iisexpress.exe' (CLR v4.0.30319: /LM/W3SVC/2/ROOT-1-131748725731267230): Loaded 'C:UsersXyzAppDataLocalTempTemporary ASP.NET Filesvs9d633996538b9a4aApp_Web__loginlayout.cshtml.a8d08dba.ih2qhxwq.dll'.
I teraz najlepsze: możemy tego dokonać za pomocą narzędzi udostępnionych w ramach biblioteki System.Reflection.Emit, będącej częścią ”starego” .NET-u, a w przypadku .NET Core dystrybuowanej za pomocą NuGet-a (wchodzi w skład domyślnej paczki SDK Microsoft.NETCore.App więc w większości przypadków nie trzeba go instalować ręcznie).
Zatrzymajmy się na chwilę. W kolejnej części artykułu, który opublikujemy w piątek, cofniemy się do naszego prototypu i pokażę Wam typy z Ikei, do samodzielnego montażu, które możecie wykorzystać w swoich projektach.
Podobne artykuły

Python w 2026 – do czego służy, jak zacząć i dlaczego warto?

Programista kwantowy – czy warto uczyć się Qiskit w 2026 roku?

Krytyczne spojrzenie na kod jest kluczowy dla jego skutecznej analizy. Jak analizować systemy legacy

Sieci neuronowe. PyTorch i praktyczny projekt od początku do końca

Od czego zacząć swoją przygodę w branży IT? Rozmowa z Jackiem Hrynczyszynem, Java Developerem

Kim jest Software Architect? Obowiązki, specjalizacje, kariera

Co nowego w Javie? Przegląd zmian, które przyniosło JDK 20
