Transfer Learning w Computer Vision. Dostosowanie wstępnie wytrenowanych modeli ramowych do domen biznesowych
Transfer learning (nauczanie transferowe) stał się popularną techniką w Computer Vision, umożliwiając trenowanie głębokich sieci neuronowych przy ograniczonej ilości danych poprzez wykorzystanie wstępnie wytrenowanych modeli. W tym artykule dokonujemy przeglądu ostatnich postępów w nauczaniu transferowym do zadań Computer Vision, w tym klasyfikacji obrazów, wykrywania obiektów, segmentacji semantycznej i innych.
Omawiamy różne podejścia do nauczania transferowego, takie jak dostrajanie, ekstrakcja cech i adaptacja domeny, a także podkreślamy wyzwania i ograniczenia każdego podejścia. Przedstawiamy również przegląd popularnych wstępnie wytrenowanych modeli i zbiorów danych wykorzystywanych do nauczania transferowego oraz omawiamy przyszłe kierunki i możliwości badań w tej dziedzinie.
Spis treści
Computer Vision
Computer Vision to dziedzina sztucznej inteligencji (AI) i informatyki, która koncentruje się na umożliwieniu maszynom interpretowania, rozumienia i analizowania danych wizualnych z otaczającego nas świata. Celem Computer Vision jest stworzenie inteligentnych systemów mogących wykonywać zadania, które normalnie wymagają percepcji wzrokowej na poziomie ludzkim, takie jak wykrywanie obiektów, rozpoznawanie, śledzenie i segmentacja.
Computer Vision obejmuje szeroki zakres technik i podejść, umożliwiając modelom uczenie się na podstawie dużych ilości danych wizualnych, takich jak obrazy i filmy. W ostatnim czasie odnotowano wiele osiągnięć w dziedzinie Computer Vision, napędzanych w dużej mierze przez postępy w głębokim uczeniu i sieciach neuronowych. Oto kilka godnych uwagi przykładów:
- Generowanie obrazów GPT-3: Model językowy GPT-3, opracowany przez OpenAI, został niedawno wykorzystany do generowania realistycznych obrazów na podstawie opisów tekstowych. Poprzez warunkowanie sieci neuronowej na opisach w języku naturalnym, model jest w stanie generować szczegółowe obrazy, które dokładnie oddają opisywaną scenę.
- Wykrywanie obiektów: Najnowsze, najnowocześniejsze modele wykrywania obiektów osiągają wysoką dokładność w różnych zestawach danych, w tym COCO, Pascal VOC i ImageNet. Modele te opierają się na architekturze głębokiego uczenia, takich jak Faster R-CNN, RetinaNet i YOLOv5, i wykorzystują techniki takie jak piramidy cech i skrzynki kotwiczne w celu poprawy dokładności i szybkości.
- Pojazdy autonomiczne: Computer Vision jest kluczową technologią umożliwiającą autonomicznym pojazdom nawigację i interpretację ich otoczenia. Najnowsze osiągnięcia w tej dziedzinie obejmują platformę DRIVE AGX firmy NVIDIA, która wykorzystuje algorytmy głębokiego uczenia się po to, aby umożliwić percepcję i podejmowanie decyzji w pojazdach autonomicznych w czasie rzeczywistym.
- Obrazowanie medyczne: Computer Vision jest również wykorzystywany do poprawy obrazowania medycznego, a najnowsze postępy obejmują systemy oparte na sztucznej inteligencji do diagnozowania raka płuc i wykrywania retinopatii cukrzycowej.
- Robotyka: Computer Vision ma kluczowe znaczenie dla umożliwienia robotom postrzegania i interakcji z otaczającym je światem. Najnowsze osiągnięcia obejmują systemy oparte na głębokim uczeniu się do rozpoznawania obiektów, chwytania optycznego i manipulacji.
Computer Vision jest aktywną i szybko rozwijającą się dziedziną, w której ciągle pojawia się wiele nowych technik i zastosowań. Ma ona potencjał, by zrewolucjonizować wiele branż i zmienić sposób, w jaki wchodzimy w interakcje z maszynami i otaczającym nas światem. W centrach kompetencyjnych Sigma Software już teraz zauważamy stale rosnący popyt ze strony firm i spodziewamy się, że może on nawet wzrosnąć wykładniczo w ciągu najbliższych 6-12 miesięcy, wraz z szerszą adaptacją dużych modeli.
Przyjrzyjmy się kilku powszechnym zadaniom, które Computer Vision już dziś pomaga wykonywać i które mogą być stosowane w wielu dziedzinach biznesu:
- Wykrywanie obiektów: identyfikowanie i lokalizowanie obiektów na obrazie lub wideo
- Rozpoznawanie obrazów: klasyfikowanie obrazów na podstawie ich zawartości
- Rozpoznawanie twarzy: identyfikacja i weryfikacja tożsamości osoby na podstawie jej rysów twarzy
- Pojazdy autonomiczne: umożliwienie pojazdom nawigowania i interpretowania ich otoczenia przy użyciu danych wizualnych
- Obrazowanie medyczne: analiza obrazów medycznych w celu wykrywania i diagnozowania chorób
- Rzeczywistość rozszerzona: nakładanie informacji cyfrowych na obrazy lub filmy świata rzeczywistego
- Handel detaliczny i e-commerce: w celu poprawy rekomendacji produktów i wyszukiwania wizualnego
- Rolnictwo: w celu poprawy wydajności upraw i zmniejszenia szkód w uprawach
Oczywiście Computer Vision ma również swoje własne wyzwania. Jednym z najważniejszych jest zapotrzebowanie na duże ilości danych opatrzonych przypisami do trenowania dokładnych modeli. Gromadzenie i opisywanie dużych zbiorów danych może być kosztowne i czasochłonne, a często wymaga specjalistycznej wiedzy. Co więcej, różne zadania i dziedziny mogą wymagać różnych typów danych i adnotacji, co utrudnia ponowne wykorzystanie istniejących już zbiorów danych.
Transfer Learning — nauczanie metodą transferu
Transfer learning odpowiada na te wyzwania, umożliwiając nam ponowne wykorzystanie wstępnie wytrenowanych modeli i zbiorów danych do nowych zadań i dziedzin. Używając wstępnie wytrenowanego modelu jako punktu wyjścia (często nazywanego modelem ramowym), możemy zmniejszyć ilość nowych danych i adnotacji wymaganych do wytrenowania nowego modelu i poprawić jego wydajność w zadaniu docelowym. Koncepcje nauczania transferowego w uczeniu maszynowym i ludzkim mózgu są powiązane, ale podstawowe mechanizmy i procesy są różne.
- W nauczaniu maszynowym Transfer Learning polega na wykorzystaniu modeli, które zostały już wytrenowane na dużym zbiorze danych dla określonego zadania. Modele te są następnie dostrajane na mniejszym zbiorze danych dla powiązanego zadania, co pozwala im szybciej uczyć się i dostosowywać do niego. Proces ten może znacznie poprawić wydajność i dokładność procesu uczenia się, ponieważ wstępnie wytrenowane modele nauczyły się już rozpoznawać pewne cechy i wzorce, które mogą być zastosowane do nowego zadania.
- Nauczanie transferowe w mózgu odnosi się do zdolności ludzi do stosowania wiedzy i umiejętności w wielu różnych kontekstach. Na przykład komuś, kto nauczył się grać na pianinie, może być łatwiej nauczyć się grać na innym instrumencie, takim jak gitara, ponieważ rozwinął już odpowiednie umiejętności, które może zastosować w nowym kontekście. Ta zdolność do przenoszenia wiedzy między różnymi kontekstami jest podstawowym aspektem ludzkiego uczenia się i inteligencji.
Wstępnie wytrenowane sieci neuronowe
Istnieje kilka wstępnie wytrenowanych sieci neuronowych, które zyskały znaczną popularność i były szeroko stosowane w różnych aplikacjach Computer Vision. Oto niektóre z najbardziej znanych:
1. VGG (Visual Geometry Group): to rodzina głębokich sieci neuronowych, które osiągnęły najwyższą wydajność w ImageNet Challenge 2014. Modele VGG charakteryzują się głęboką architekturą, z maksymalnie 19 warstwami, i były szeroko stosowane w różnych zadaniach Computer Vision, takich jak rozpoznawanie obiektów i lokalizacja.
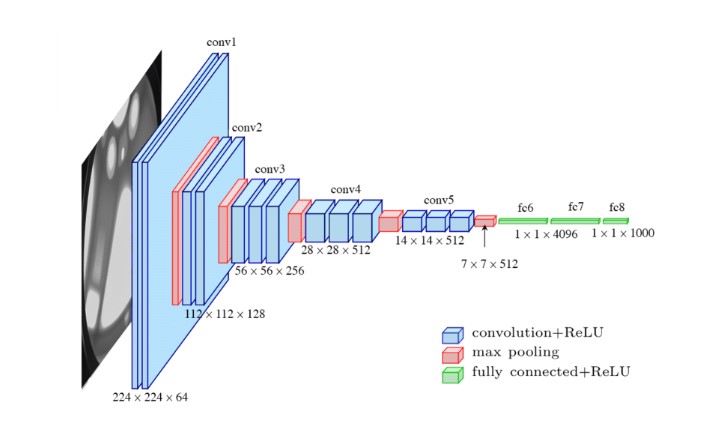
2. ResNet (Residual Network): to kolejna rodzina głębokich sieci neuronowych, która wygrała ImageNet Challenge w 2015 roku. Modele ResNet charakteryzują się blokami resztkowymi, które pozwalają na łatwiejsze trenowanie bardzo głębokich sieci neuronowych z ponad 100 warstwami. Modele ResNet są szeroko stosowane w różnych zadaniach Computer Vision, takich jak rozpoznawanie i wykrywanie obiektów.
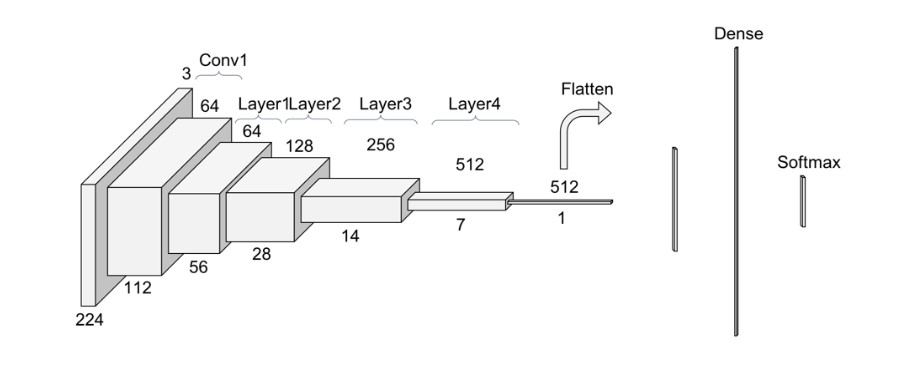
3. Inception: to rodzina głębokich sieci neuronowych wprowadzona przez Google w 2014 roku. Modele Inception charakteryzują się wykorzystaniem wielu równoległych warstw konwolucyjnych w różnych skalach do wyodrębniania cech z obrazów. Modele te są szeroko stosowane w różnych zadaniach Computer Vision, takich jak klasyfikacja obrazów i wykrywanie obiektów.
4. MobileNet: to rodzina głębokich sieci neuronowych zaprojektowana dla urządzeń mobilnych i wbudowanych z ograniczonymi zasobami obliczeniowymi. Modele MobileNet charakteryzują się lekką architekturą, która umożliwia szybkie wnioskowanie na urządzeniach mobilnych. Są szeroko stosowane w różnych zadaniach Computer Vision, takich jak rozpoznawanie i wykrywanie obiektów na urządzeniach mobilnych.
Te wstępnie wytrenowane sieci neuronowe zostały udostępnione publicznie i były szeroko stosowane jako punkt wyjścia do nauczania transferowego w wielu aplikacjach Computer Vision. Więcej informacji na temat różnych modeli można znaleźć na stronach TensorFlow Model Garden i PyTourch Hub — dwóch najpopularniejszych frameworkach nauczania głębokiego.
Szkolenie lokalne i w chmurze
Jeśli chodzi o szkolenie dużych modeli wizualnych, istnieją korzyści zarówno dla szkolenia lokalnego, jak i w chmurze. Lokalne szkolenie pozwala mieć pełną kontrolę nad sprzętem i oprogramowaniem używanym do szkolenia, co może być korzystne w przypadku niektórych zastosowań. Można wybrać konkretne komponenty sprzętowe, takie jak procesory graficzne (GPU) lub procesory tensorowe (TPU) i zoptymalizować swój system pod kątem konkretnego zadania. Lokalne szkolenie zapewnia również większą kontrolę nad procesem treningu, umożliwiając dostosowanie jego parametrów i łatwiejsze eksperymentowanie z różnymi technikami.
Lokalne trenowanie dużych modeli wizualnych może być jednak wymagające obliczeniowo i może wymagać znacznych zasobów sprzętowych, takich jak wysokiej klasy procesory graficzne lub TPU, które często są drogie. Ponadto proces uczenia może zająć dużo czasu, potencjalnie kilka dni lub nawet tygodni, w zależności od wielkości modelu i złożoności zbioru danych.
Szkolenie w chmurze może przynieść szereg korzyści, w tym dostęp do potężnych zasobów sprzętowych, takich jak TPU i procesory graficzne, oraz skalowalność. Dostawcy usług w chmurze, tacy jak Amazon Web Services (AWS), Google Cloud Platform (GCP) i Microsoft Azure, oferują oparte na chmurze platformy uczenia maszynowego, które zapewniają wstępnie skonfigurowane środowiska do szkolenia i wdrażania modeli uczenia maszynowego. Platformy oparte na chmurze umożliwiają również łatwe skalowanie w górę lub w dół w zależności od wielkości zbioru danych i złożoności modelu, zapewniając opłacalne rozwiązania zarówno dla małych, jak i dużych projektów.
Szkolenie w chmurze może jednak wiązać się z dodatkowymi kosztami, takimi jak koszty transferu i przechowywania danych, a także wymagać dodatkowej konfiguracji. Ponadto korzystanie z usług w chmurze może budzić obawy dotyczące bezpieczeństwa i prywatności, dlatego ważne jest, aby upewnić się, że dane są chronione i przetwarzane zgodnie z obowiązującymi przepisami.
Przypadki użytkowników
Aby lepiej „poczuć”, jak działa transfer learning, przyjrzyjmy się bliżej konkretnemu przypadkowi użytkownika z branży detalicznej/modowej. Załóżmy, że firma detaliczna chce ulepszyć swój system rekomendacji produktów, sugerując klientom podobne produkty w oparciu o pewne preferencje. Firma posiada duży katalog zdjęć produktów i chce stworzyć dokładny i wydajny system rekomendacji, który może uczyć się na podstawie zachowań i opinii klientów. Więcej szczegółów na temat jednego z takich modeli, w tym kod Pythona, można znaleźć w raporcie GitHub Fashion-Recommendation-System.
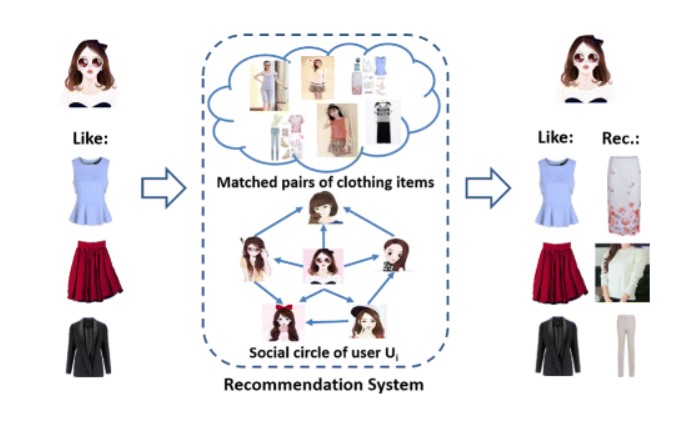
Jednym ze sposobów na osiągnięcie tego celu jest zbudowanie modelu rekomendacji od podstaw, ale będzie to kosztować wiele zasobów, więc zamiast tego firma może użyć wstępnie wytrenowanego modelu konwolucyjnej sieci neuronowej (CNN), takiego jak VGG, który został już przeszkolony na dużym zbiorze danych obrazów.
Wstępnie wytrenowana CNN może być precyzyjnie dostrojona do obrazów produktów firmy detalicznej, aby rozpoznawać ogólne lub nawet specyficzne cechy i atrybuty produktów, takie jak kolor, tekstura, kształt, które będą związane konkretnie z obrazami produktów firmy, a nie z ogólnym zestawem obrazów.
Gdy wstępnie wytrenowana CNN zostanie dostrojona do obrazów produktów firmy detalicznej, można jej użyć do wygenerowania osadzeń dla każdego produktu. Te osadzenia reprezentują unikalne cechy każdego produktu, które model nauczył się rozpoznawać. Osadzenia można następnie wykorzystać do porównywania i znajdowania podobieństw między produktami.
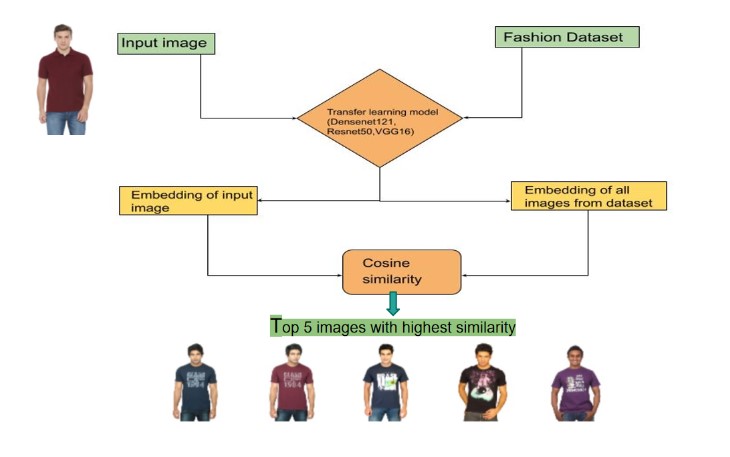
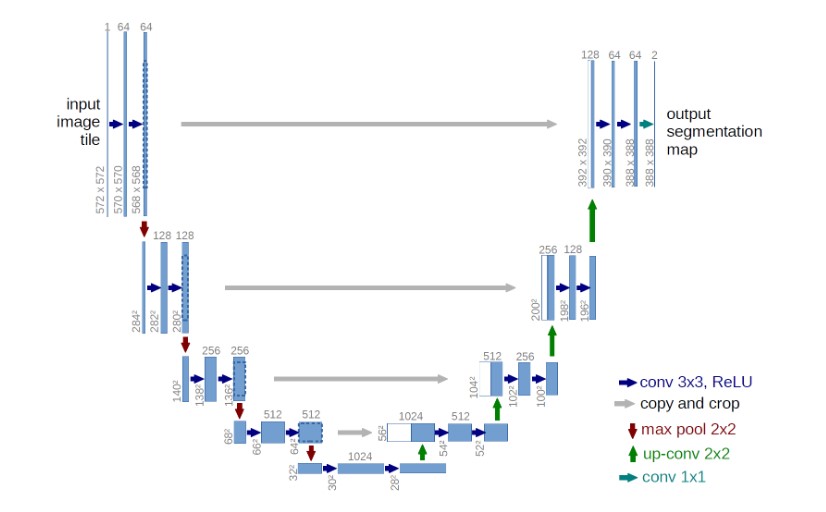
Ogólnie rzecz biorąc, osadzanie nie odbywa się w formie czytelnej dla człowieka (jak kolor, tekstura), ale zamiast tego reprezentowane jest w postaci współczynników wagowych ostatniej warstwy sieci neuronowej. Najpopularniejszym sposobem znajdowania podobieństw w takiej formie jest wykorzystanie odległości cosinusowej. Więcej szczegółów, w tym pełną implementację kodu opartą na FCNN, sieci neuronowej U-Net można znaleźć w notatniku Kaggle (Get Started With Semantic Segmentation).
W rezultacie, gdy klient wchodzi w interakcję z systemem rekomendacji, jego zachowanie i preferencje są rejestrowane, a ich osadzenia są generowane. Następnie, system porównuje osadzenia klienta z osadzeniami katalogu produktów firmy i sugeruje produkty, które są najbardziej podobne do preferencji klienta.

Transfer Learning. Podsumowanie
Podsumowując wszystkie powyższe rozważania, możemy stwierdzić, że nauczanie transferowe okazało się skuteczną techniką poprawy wydajności komputerowych modeli wizyjnych w różnych zastosowaniach biznesowych. Wykorzystując wstępnie wytrenowane modele, nauczanie transferowe pozwala firmom znacznie zmniejszyć ilość etykietowanych danych szkoleniowych wymaganych do szkolenia i dostrajania modeli. Może to skutkować znacznymi oszczędnościami i szybszym wprowadzaniem na rynek nowych produktów i funkcji.
W handlu elektronicznym nauczanie transferowe może być wykorzystywane do ulepszania systemów wyszukiwania i rekomendacji produktów, automatyzacji tagowania i kategoryzacji produktów oraz włączania funkcji wyszukiwania wizualnego. Transfer learning może być również wykorzystywany do poprawy analizy obrazu i wideo w zadaniach takich jak kontrola jakości produktu i inspekcja wizualna.
Chociaż istnieją wyzwania związane z wdrażaniem uczenia transferowego w różnych domenach biznesowych, takie jak znalezienie i dostosowanie odpowiednich wstępnie wytrenowanych modeli do konkretnej domeny i zbioru danych, korzyści są znaczące. Wykorzystując uczenie transferowe, firmy mogą poprawić dokładność i wydajność swoich modeli Computer Vision, co prowadzi do lepszej obsługi klienta i zwiększenia przychodów.
Podobne artykuły

Computer Vision - rozpoznawanie treści na obrazach tak, jak robi to ludzki mózg

Zespół AI jest o tyle trudny do stworzenia, że wymaga wielu kompetencji. Devdebata

"Chciałabym, aby sztuczna inteligencja była powszechnie wykorzystywana w medycynie" - wywiad z Agnieszką Mikołajczyk
