Wszystko, co powinieneś wiedzieć, zanim zaczniesz pracę z blockchainem
O popularności technologii blockchain nie trzeba nikogo przekonywać. Do końca czerwca br. termin ten został użyty w ponad 86 mln publikacji w sieci czy ponad 27 tys. repozytoriów na githubie. Rośnie liczba wyszukiwań zawierających tę frazę, kryptowalut, startup’ów oraz opartych na tej technologii projektów inicjowanych przez liderów branży IT oraz instytucje finansowe. Czy zjawisko to jest sygnałem zbliżającej się rewolucji technologicznej czy raczej kolejną “bańką”? Aby to ocenić, należy dokładniej przyjrzeć się, czym tak naprawdę jest blockchain.
Robert Kuśmierek. Lead Software Engineer w ASC LAB. Altkom Software & Consulting należy do polskiej grupy Altkom. W ASC skupiają się osoby lubiące tworzyć rozwiązania technologiczne, jednocześnie spędzając czas razem. Firma najbardziej ceni chęć rozwoju, zaangażowanie oraz podejście do kodowania. Tę organizację tworzą osoby pełne pasji, dlatego odwdzięcza się elastycznym podejściem do pracownika i jego oczekiwań.
Zacznijmy od kilku podstawowych pojęć.
Spis treści
Funkcja mieszająca (hash function)
Funkcją mieszającą nazywamy operację przekształcającą dowolnie długi ciąg znaków w ciąg o ustalonej długości i posiadającą następujące właściwości:
- bezkolizyjność (collision-free) – przez bezkolizyjność nie rozumiemy tu, że kolizje nie istnieją, ale że trudno jest znaleźć dwie wartości x i y takie, że H(x) = H(y),
- ukrywanie (hiding) – dla danej wartości y=H(x) trudno jest znaleźć x,
- puzzle-friendly – dla każdej wartości y, jeśli k jest wartością wybraną losowo (high min-entropy distribution) trudno jest znaleźć x takie, że H(k.x)=y.
Funkcje mieszające pozwalają nam generować tzw. skróty dokumentów (message digest) dlatego są również nazywane funkcjami skrótu.
Hash Pointer
Hash pointer to struktura danych zawierająca wskazanie na lokalizację, w której znajdują się dane wraz z ich skrótem. To pozwala nam zlokalizować informacje oraz potwierdzić, że nie uległy zmianie.

Blockchain
Mechanizm hash pointer’ów możemy zastosować w podstawowej strukturze danych, jaką jest lista, aby uzyskać kolejną strukturę danych – popularnie nazywaną łańcuchem bloków (blockchain). Każdy element listy zawiera hash pointer, czyli wskaźnik i skrót kryptograficzny do poprzedniego elementu:

Modyfikacja dowolnego bloku spowodowałaby zmianę jego skrótu, a co za tym idzie wymagałaby aktualizacji hash pointera zawartego w jego następniku, co z kolei wymusiło by kaskadową aktualizację wszystkich kolejnych bloków, aż do “głowy”. Dlatego też, informacje będziemy wprowadzali do łańcucha przez dodanie nowego bloku na jego końcu:

Niezmienność Blockchain’a
Uzyskana w ten sposób struktura danych posiada kryptograficzną gwarancję niezmienności (immutability). Oznacza to, że nie jest możliwe dodanie, usunięcie lub zmiana dowolnego z elementów łańcucha bez modyfikacji jego “głowy” (dla ścisłości należy dodać, że jest to teoretycznie możliwe, jednak w praktyce niewykonalne, ponieważ wymagałoby wygenerowania kolizji wykorzystywanej funkcji skrótu). Metodami kryptograficznymi nie jesteśmy natomiast w stanie zagwarantować niezmienności “głowy”, a co za tym idzie absolutnej niezmienności całego łańcucha. Wrócimy do tego zagadnienia w dalszej części tekstu.
Replikacja
Aby uodpornić nasz łańcuch na zmiany, czy to będące wynikiem awarii, czy też celowej ingerencji, możemy zastosować replikację. Zakładamy tu, że jeśli niepożądana modyfikacja dotknie stosunkowo niewielkiej liczby kopii, będziemy w stanie ją łatwo zidentyfikować i tym samym określić, która wersja danych jest “prawdziwa”, a która “fałszywa”.

Aby jednak taka replikacja mogła posłużyć jako faktyczne zabezpieczenie łańcucha, poszczególne kopie muszą funkcjonować niezależnie – zarówno w sensie technicznym, tzn. znajdować się na osobnych serwerach, w różnych lokalizacjach, jak i organizacyjnym, czyli być zarządzane przez osobnych administratorów, którzy nie posiadają wspólnego przełożonego ani powiązań kapitałowych.
Konsensus
Jeśli w naszym systemie pojawią się dwie różne wersje łańcucha, w jaki sposób ustalimy, która z nich jest tą właściwą?

Problem uzgadniania w systemach rozproszonych został sformułowany w 1980 roku przez Marshalla Pease’a, Leslie Lamporta i Roberta Shostaka jako Problem Bizantyjskich Generałów.
Generałowie oblegający miasto muszą podjąć wspólną decyzję dotyczącą ataku lub odwrotu. Jeśli nie uda im się osiągnąć konsensusu (np. tylko część generałów zaatakuje) silniejszy przeciwnik pokona rozproszone armie.

Konsensus w sieciach zamkniętych
Obecnie dysponujemy kilkoma algorytmami adresującymi problem uzgadniania, z których jednym z najczęściej stosowanych w rozwiązaniach bazujących na blockchainie, jest zaproponowany w 1999 roku przez Miguela Castro i Barbarę Liskov algorytm PBFT (Practical Byzantine Fault Tolerance). Nie będziemy tu opisywać sposobu jego działania. Trzeba jednak zwrócić uwagę na dwie kwestie.
Po pierwsze, algorytm ten gwarantuje żywotność (liveness) oraz bezpieczeństwo (safety) przy założeniu, że co najwyżej (N-1)/3 spośród N kopii zachowuje się niepoprawnie. Możemy też odwrócić tę zależność. Jeżeli zakładamy, że f kopii może w danej chwili zachować się błędnie, potrzebujemy 3f+1 replik, aby zapewnić pożądany efekt działania algorytmu.
Po drugie, do poprawnego funkcjonowania, algorytm ten wymaga wcześniejszego ustalenia listy uczestników protokołu, co praktycznie ogranicza jego wykorzystanie do zastosowań zamkniętych (private blockchain). Jak łatwo zauważyć, oznacza to również, że ten kto kontroluje członkostwo może wpływać na wynik działania protokołu poprzez włączanie do sieci węzłów realizujących decyzje zgodne z jego intencją, i/lub wyłączając z sieci węzły, które działają inaczej.
Konsensus w sieciach otwartych
W sieciach otwartych (public blockchain), brak mechanizmów uwierzytelnienia i kontroli członkostwa otwiera dodatkowo możliwość wykonywania ataków typu “Sybil”. Dlatego też, w takich warunkach przeważnie stosuje się schematy typu LCCR (Longest Chain Consensus Rule), w których za prawdziwą wersję uznajemy najdłuższy łańcuch, ale wprowadzamy ograniczenie częstotliwości, z jaką mogą być tworzone kolejne bloki. Do najpopularniejszych algorytmów z tej grupy należą:
- proof-of-work – aby móc do łańcucha dołączyć kolejny blok należy przedstawić dowód rozwiązania odpowiednio złożonego problemu obliczeniowego. Wadą tego podejścia jest koszt energii potrzebnej do wykonania niezbędnej pracy;
- proof-of-stake – tu wybór wersji łańcucha następuje przez oddanie głosów, których waga zależy od ilości “postawionych” środków. To podejście ma jednak poważną ułomność znaną pod nazwą nothing-at-stake;
Schematy typu LCCR / proof-of-xxx są jednak podatne na ataki typu 51%, co oznacza, że ten kto kontroluje powyżej połowy zasobów stanowiących podstawę działania danego algorytmu (czyli mocy obliczeniowej w przypadku PoW lub środków – w przypadku PoS) decyduje de facto o obowiązującej wersji łańcucha. Nie jest to podatność teoretyczna. W sieci można znaleźć wiele informacji o tego typu incydentach – patrz na przykład ostatni atak na Verge.
Warto również zwrócić uwagę, że dla algorytmów LCCR w sieci otwartej nie istnieje pojęcie stopu. Z biegiem czasu maleje jedynie prawdopodobieństwo zmiany aktualnie obowiązującej wersji łańcucha. Przykładowo, w przypadku Bitcoina, blok uznaje się za “potwierdzony”, kiedy za nim w łańcuchu pojawi się 6 kolejnych, co przy średnich odstępach czasowych pomiędzy blokami rzędu 10 minut następuje po około godzinie.
Drzewo skrótów (Merkle Tree)
Ze względów praktycznych łańcuch zwykle nie przechowuje pełnych danych. Zamiast tego w bloku zwykle umieszcza się ich skrót albo, wynalezione w 1979 roku przez Ralpha Merkle, drzewo skrótów (Merkle Tree).

Zastosowanie drzewa skrótów pozwala na oddzielenie danych, których niezmienność chcemy zabezpieczyć za pomocą blockchaina, od samego łańcucha. Dzięki temu, możemy repliki podzielić na dwie kategorie:
- pełne – przechowujące zarówno łańcuch, jak i dane,
- częściowe – przechowujące tylko łańcuch.
Jest to szczególnie przydatne w przypadku:
- danych o dużym wolumenie,
- dużej liczby obiektów (udowodnienie przynależności węzła do drzewa jest operacją o złożoności logarytmicznej),
- danych o charakterze niejawnym.
Ze względu na swoją specyfikę, blockchain nie powinien być traktowany jako zamiennik dla tradycyjnej bazy danych. Dobrą praktyką jest pozostawienie informacji w przystosowanej do tego celu bazie (relacyjnej, dokumentowej, itp) a umieszczenie w łańcuchu jedynie skrótów. W ten sposób zachowujemy rolę “dowodową” blockchaina przy minimalizacji jego rozmiaru.
Reguły
Do tej pory zajmowaliśmy się blockchainem, jako strukturą danych posiadającą cechę niezmienności (immutability) pomijając rozważania nad tym, co dokładnie chcielibyśmy w nim przechowywać. Skoro wiemy już, jak uzyskać niezmienność łańcucha, chcielibyśmy teraz zapewnić, aby trafiające do niego informacje były poprawne.
Przykładowo, w przypadku zasobów (assets), oczekujemy, że każdy użytkownik może dysponować tylko własnymi środkami oraz, że nie będzie można wprowadzić do blockchaina transakcji przelewu większej ilości środków, niż znajdujące się w dyspozycji użytkownika zlecającego. Dodatkowo, w przypadku kryptowalut chcielibyśmy ograniczyć częstotliwość emisji “monet”, aby nie dopuścić do dewaluacji. Tworząc oparte na blockchainie repozytorium dokumentów potrzebujemy zapewnić, że stempel czasowy, którym opatrzony jest nowo dodany plik nie będzie starszy niż data i czas ostatnio zapisanego dokumentu, ani nie będzie się znajdował w przyszłości.
Aby zapewnić spójność danych, walidację takich reguł musimy wbudować w protokół komunikacji pomiędzy replikami, jako rozszerzenie opisanego wcześniej algorytmu konsensusu. Mechanizm należy zaimplementować w taki sposób, aby tylko te wersje łańcucha, które spełniają zdefiniowane przez nas reguły mogły być brane pod uwagę podczas uzgadniania obowiązującej wersji łańcucha.
Trzeba jednak pamiętać, że w systemie rozproszonym nie mamy gwarancji, że wszystkie węzły zastosują tę samą logikę walidacji. Na skutek awarii lub celowej ingerencji w tryby protokołu konsensusu może dostać się wersja łańcucha wspierana przez część węzłów a odrzucana przez pozostałe. Końcowy wynik uzgodnień będzie w takiej sytuacji zależał od zastosowanego algorytmu oraz rozłożenia sił zwolenników i przeciwników poszczególnych wersji łańcucha.
Blockchain jako platforma
Walidację reguł możemy zrealizować na dwa sposoby:
- wbudowując logikę “na sztywno” w protokół;
- wbudowując w protokół odpowiedni język, pozwalający na implementację reguł.
Pierwsze podejście ogranicza wykorzystanie łańcucha do jednego zastosowania – określonego ściśle przez zaimplementowany zestaw reguł. Wybierając drugie podejście przekształcamy łańcuch w platformę, którą możemy następnie wykorzystać do wielu różnych zastosowań.
Konstruując opartą na blockchainie platformę należy zwrócić uwagę, że mamy tu do dyspozycji dwie kategorie języków: posiadające cechę kompletności Turinga (np. używany w Ethereum język Solidity) i niekompletne w sensie Turinga (np. Bitcoin Script, który, jak sama nazwa wskazuje, wykorzystuje sam Bitcoin oraz bazujący na nim Multichain). Te pierwsze mają znacznie większą siłę wyrazu, ponieważ można za ich pomocą zaimplementować dowolnie złożoną logikę. Z drugiej jednak strony, w ogólnym przypadku nie jesteśmy w stanie apriori stwierdzić, ile czasu zajmie wykonanie programu napisanego w takim języku oraz czy kiedykolwiek się on zatrzyma. Zbyt złożona logika walidacji reguł spowoduje wydłużenie czasu potrzebnego do osiągnięcia konsensusu i może stanowić zagrożenie dla stabilności całego protokołu.
Inteligentne Umowy (Smart Contracts)
Szczególnym rodzajem rozwiązań, jakie możemy budować na takiej platformie, są Inteligentne Umowy (Smart Contracts). Termin ten zaproponował w 1994 roku Nick Szabo. Stało się to więc na 4 lata przed słynną wypowiedzią Wei Dai’a (1998) na jednej z list mailingowych cyberpunków, w której po raz pierwszy pojawiła się koncepcja kryptowaluty (b-money) i na 14 lat przed powstaniem pierwszego bloku Bitcoin’a (2009).
Inteligentne Umowy pozwalają zaadresować problem braku wzajemnego zaufania, bez konieczności angażowania strony trzeciej. Najprostszym przykładem są tu kontrakty typu escrow: dwie strony planują dokonać wymiany dóbr, jednak wymiana nie może zajść równocześnie, a żadna ze stron nie chce jako pierwsza zrealizować swojej części umowy obawiając się o realizację zobowiązań drugiej strony. W świecie analogowym takie okoliczności wymagały zaproszenia do stołu zaufanego pośrednika – na przykład banku. W przypadku zastosowania Inteligentnych Umów gwarantem egzekwowania postanowień kontraktu jest sam kod wykonywany przez węzły uczestniczące w danej sieci – w ramach protokołu konsensusu.
Podsumowanie
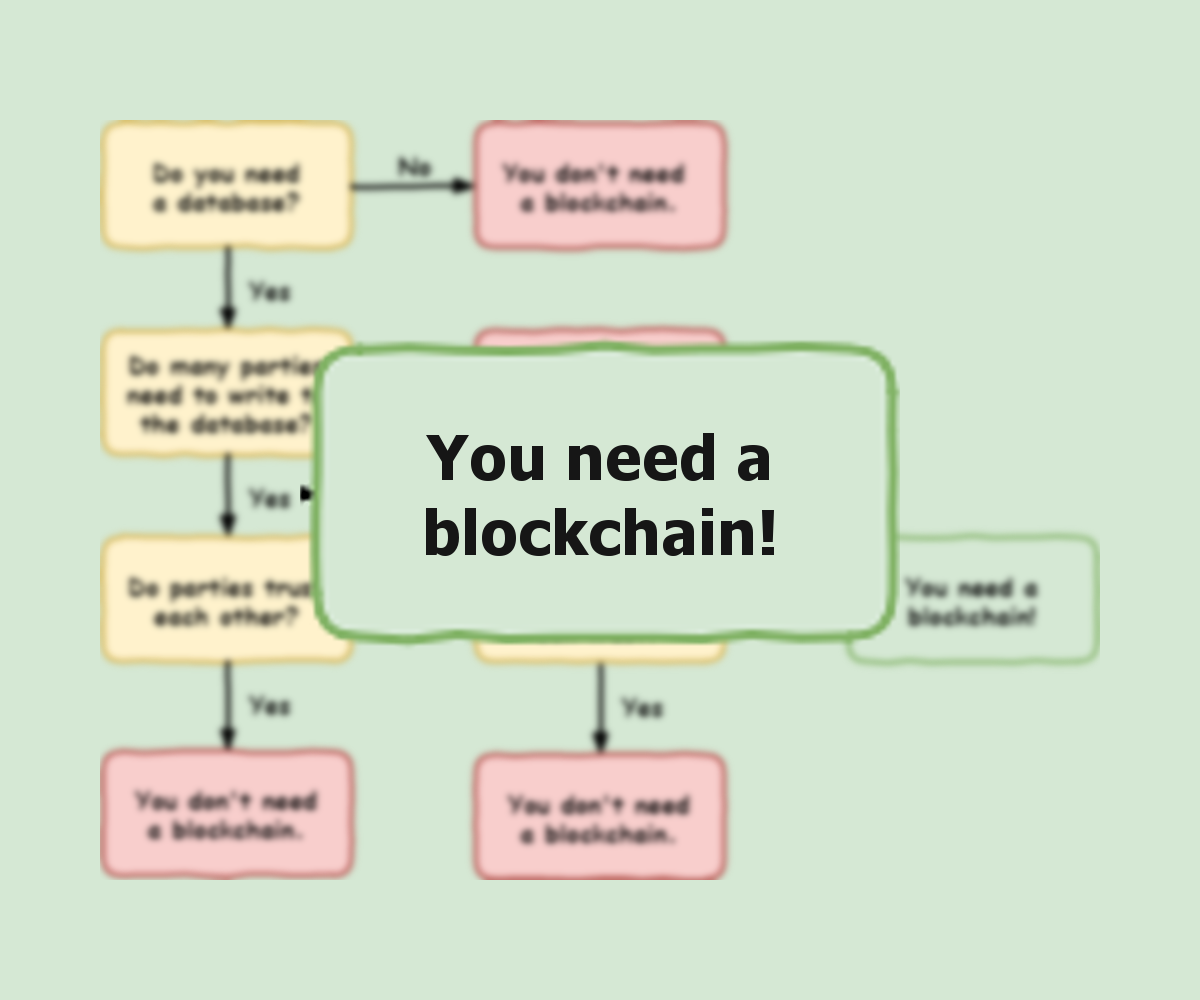
Technologie bazujące na blockchainie oferują potężne możliwości. Projektując oparte na nich rozwiązania trzeba wziąć pod uwagę dwie kwestie. Po pierwsze, nie można zapominać ograniczeniach technologii – zwłaszcza tych, które wynikają z wymagań i właściwości zastosowanego protokołu konsensusu. Po drugie, zawsze warto najpierw sprawdzić , czy blockchain jest rzeczywiście właściwym rozwiązaniem adresowanego problemu. W tym celu należy odpowiedzieć sobie na kilka prostych pytań:

Na podstawie: blogs.cisco.com
Jeśli zdecydujemy się na zastosowanie tej technologii warto też rozważyć, jaki zakres danych rzeczywiście powinien zostać zapisany w łańcuchu.
Chwila refleksji nad specyficznymi właściwościami blockchaina pozwala zauważyć, że nie jest to tak uniwersalna technologia, jak na przykład bazy danych (relacyjne czy dokumentowe) i raczej nie zrewolucjonizuje tak wielu dziedzin życia i gałęzi biznesu, jak mogłoby to wynikać z obecnej popularności.
Z drugiej strony, widać wyraźnie, że kolejne rozwiązania bazujące na tej technologii wychodzą z fazy eksperymentów i uzyskują rynkowe potwierdzenie. Poniżej wymienimy kilka ciekawszych przykładów, na które trafiliśmy podczas badań:
Blockverify • Everledger • We-trade • R3 • Chainthat
Tu, w ASC, jako inżynierowie jesteśmy fascynatami nowych technologii. Staramy się jednak, aby ich stosowanie, oprócz samej radości tworzenia, było źródłem realnej wartości.
Artykuł został pierwotnie opublikowany na Altkom Software & Consulting – Software House.
Podobne artykuły

Uważaj na fałszywe tutoriale na YouTubie. Możesz stracić pieniądze!

Piszesz smart kontrakty na EVM? Pokochasz to darmowe narzędzie!

Czy łatwo o pracę na obecnym rynku kryptowalut?

Budowa sieci blockchain w celu śledzenia pełnego cyklu życia produktów rolnych

W jaki sposób Wirex - firma działająca na rynku kryptowalut testuje transakcje finansowe Visa i Mastercard?

Przewodnik blockchain development – języki programowania i sieci

Blockchain Security Researcher to taki uczciwy haker, który znajduje dziury w systemie, nim zrobią to atakujący. Wywiad z Pawłem Rejkowiczem
